Introduction to Data Modeling Techniques
In the contemporary era driven by data analysis, data modeling has become an essential discipline to gain a competitive edge in informed decision-making. By providing a structured framework for organizing and analyzing data, data modeling plays a vital role in helping businesses uncover valuable insights, identify trends, and make data-informed decisions.
The purpose of this blog is to provide a comprehensive overview of data modeling techniques, covering both basic concepts and advanced techniques that empower businesses to unlock the full potential of their data warehouse.
What is a Data Model?

A data model refers to the process of creating a conceptual representation of data entities, their relationships, and the rules governing these relationships. It involves designing a blueprint that defines how the data is organized, stored, and accessed within a database or information system. By capturing the essential elements and characteristics of the data, a data model serves as a foundation for data management, application development, and business intelligence.
Key Components and Elements of Data Modeling Techniques
Data modeling consists of several key components that are essential to manage data. These include:
Data Model Entities
Data model entities represent real-world objects that are relevant to the business domain. They can be tangible entities like customers, products, or orders, or intangible entities like concepts, events or other business processes.
Data Model Attributes
Data model attributes describe the characteristics of entities. They provide details about the entities being modeled, such as names, descriptions, quantities, dates, or any other relevant information.
Data Elements
Data elements are the smallest building blocks of a data model. They represent individual data attributes within each entity. It is important to define data elements to ensure clarity and consistency in data representation.
By explicitly specifying the data type, length, format, and other characteristics of each attribute, it becomes clear how the data should be structured and interpreted.
Data Model Entity Relationship
Data model entity relationships define the connection between entities. They represent how entities are related to each other and help establish the business rules and constraints that govern this relationship.
Data Model Keys
Data model keys are unique identifiers used to distinguish individual instances of an entity. They ensure that each entity instance can be uniquely identified within the data model.
Data Model Cardinality and Multiplicity
Data model cardinality defines the number of occurrences of one entity that can be associated with another entity in an entity relationship. Multiplicity specifies the number of instances allowed on each side of the relationship.
Importance of Data Modeling in Database Design and Management

Data modeling plays a crucial role in the design and management of databases. Here are some reasons why creating data models is important:
Structure and Organization

Data models provide a structured approach to organize and store the data. They help identify entities, define relationships, and establish the overall structure of data elements in the database, ensuring data consistency and integrity in the information system.
Data Integrity and Quality
By defining rules and constraints, data modeling helps maintain data integrity and enforce data quality standards. This prevents redundant data, inconsistencies, and anomalies, ensuring reliable and accurate data storage.
Query Optimization
Well-designed data models enable efficient query performance. They allow for effective indexing, normalization, and optimization techniques, as well as improved data quality.
Scalability and Flexibility
Data modeling helps anticipate future data growth and business requirements. By designing scalable and flexible data models, businesses can easily adapt to changing needs and accommodate new data sources or functionalities.
Levels of Data Abstraction
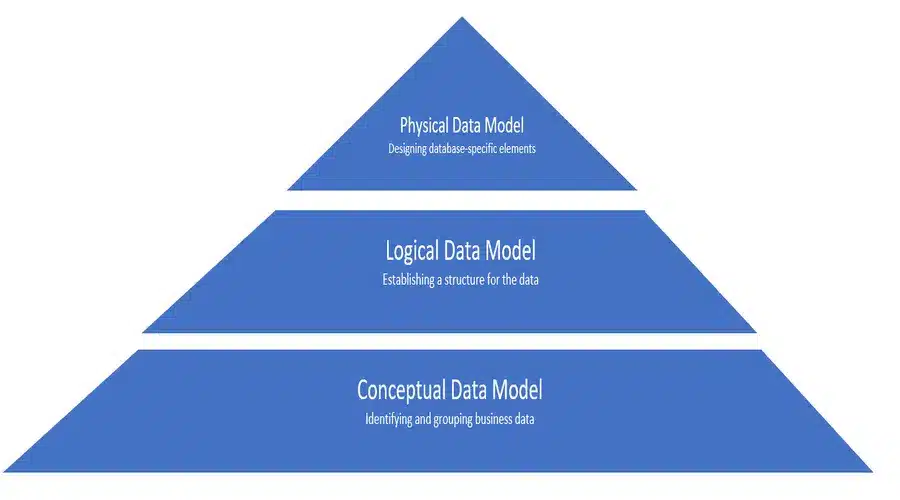
Data modeling encompasses different levels of data abstraction, resulting in three primary levels of abstraction and detail in the data modeling process:
Conceptual Data Model
A conceptual data model provides a high-level visual representation of the overall business domain and its major entities and relationships. It focuses on capturing the essential business concepts without concerning itself with the technical implementation details.
For example, a conceptual model for a customer management system for an e-commerce company might include entities like “Customer”, “Order” and “Product”, along with their relationships such as “Customer places Order” and “Order contains Product”.
The conceptual model helps business stakeholders gain a holistic view of the system and understand the business requirements.
Logical Data Model
Logical data models build upon the conceptual data model and provide a more detailed representation. They define the entities, attributes, relationships, and rules in a technology-independent manner.
Continuing with our example, the logical data modelers would specify the attributes of each entity, such as “Customer” having attributes like “Name”, “Email”, and “Address”. The logical data model would also define the cardinality of relationships, such as one-to-many between “Customer” and “Order”.
When constructing a logical model, data modelers work closely with business stakeholders to define the attributes of each entity. The attributes are chosen based on the requirements of the business and the desired functionality of the information system.
Physical Data Model
Physical data models represent the actual implementation of the data model in a specific Database Management System (DBMS). They consider the technical aspects and constraints of the chosen DBMS.
For example, the physical model would define the database tables, columns, data types, indexes, and storage structures. It would optimize how to store data and retrieve it from a relational data model. The physical data model may also include details such as defining primary keys, foreign keys, and specifying indexes on frequently queried columns.
In some cases, to be discussed later in this blog, the physical data model may involve denormalization, which is the process of combining or duplicating data to improve query performance for business analysts.
In summary, the physical model bridges the gap between the logical model and actual implementation in relational databases. It moves data modeling from a data abstraction phase to a concrete implementation phase.
Data Modeling Techniques

In the realm of data management, comprehending the popular data modeling techniques is essential for data architects to unlock the true power of an information system. Here are some commonly used types of data modeling techniques that contribute to effective data management:
Relational Data Model
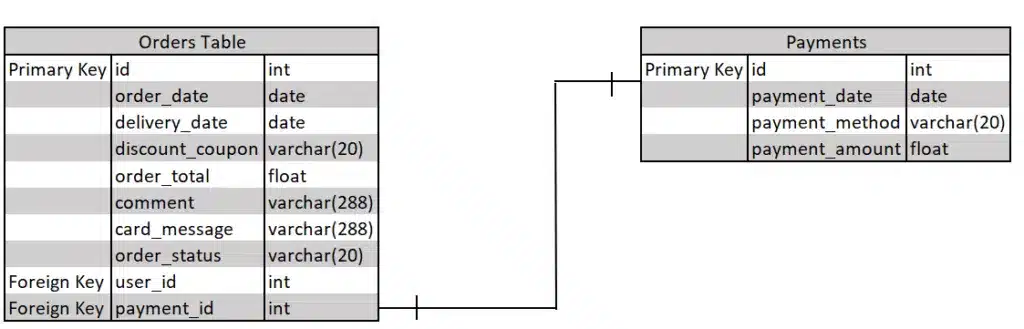
A relational model is the foundation of relational databases. It organizes data into tables consisting of rows and columns. The relationships between tables are defined through primary keys and foreign keys.
A primary key is a unique identifier within a database table that uniquely identifies each record. It ensures the uniqueness and integrity of the data in a table by serving as a reference point for other tables that establish relationships. For example, the primary key in the orders table in the figure above is the order_id, which uniquely identifies each record in the orders table.
A foreign key is a field or combination of fields with a table that establishes a link or relationship to the primary key of another table. It creates a logical connection between two tables by referencing the primary key of another table. For example, payment_id in the orders table is a foreign key that connects to the primary key of the payments table (id).
Relational data models are widely used by professional data modelers in various industries and organizations. The relational model was introduced by Edgar F. Codd in the 1970s and has since become the foundation of modern data modeling. It uses structured data, that is data formatted into tables with predefined columns and data types.
Hierarchical Model
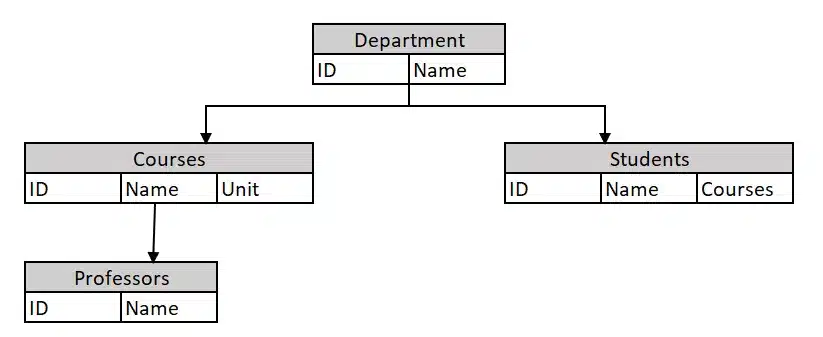
The hierarchical data model organizes data in a tree-like structure, where each record has a parent-child relationship with other records. It is commonly used in systems like XML and older mainframe databases.
The figure above gives an example of a hierarchical model where data is organized as an inverted tree. Each entity has only one parent but can have several children. At the top of the hierarchy, there is one entity, which is called the root.
Network Data Model
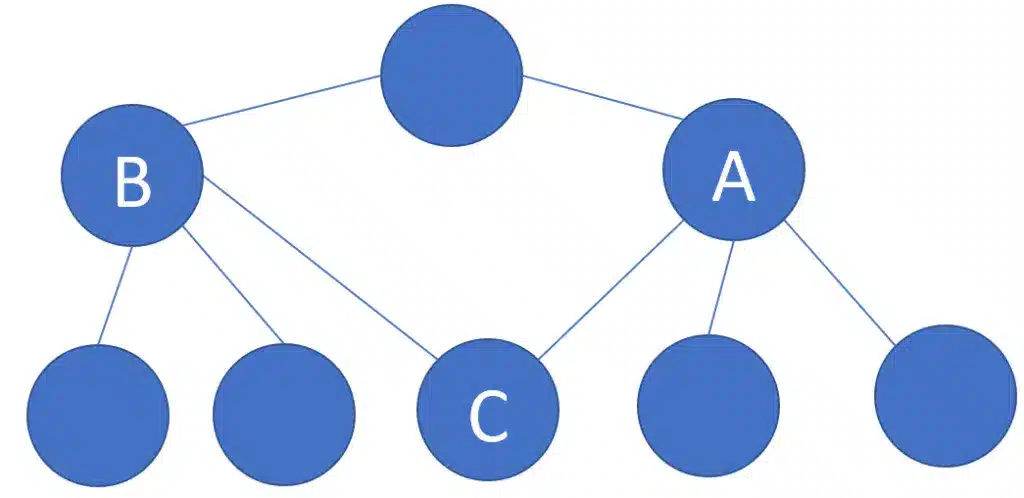
The network model is similar to the hierarchical model but allows for more complex relationships by allowing records to have multiple parent records. It was used in early database systems and is now mostly found in legacy systems.
In the figure above, notice how C has multiple parents: A and B. What differentiates a network model from a hierarchical one is that the former allows records to have multiple parents.
Object oriented model
Object oriented data modeling represents data objects, which encapsulate both data and behaviors. It allows for modeling of complex real-world entities with their properties and relationships.
Graph Data Model
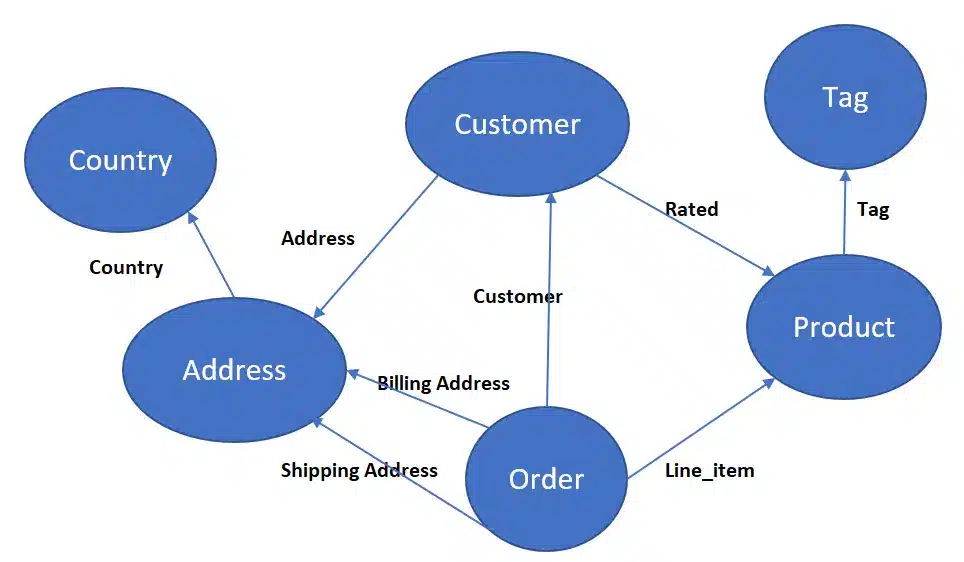
The graphical format of a data model represents data as nodes and edges, where nodes represent entities or objects, and edges represent relationships between them. The graph data modeling technique is well-suited for representing complex relationships and performing graph-based queries and analysis.
Entity Relationship (ER) Model
The entity relationship model is a conceptual data modeling tool that represents entities, attributes, and relationships between entities. It is often used in the early stages of database design for a visual representation of the data structure.
Dimensional data models
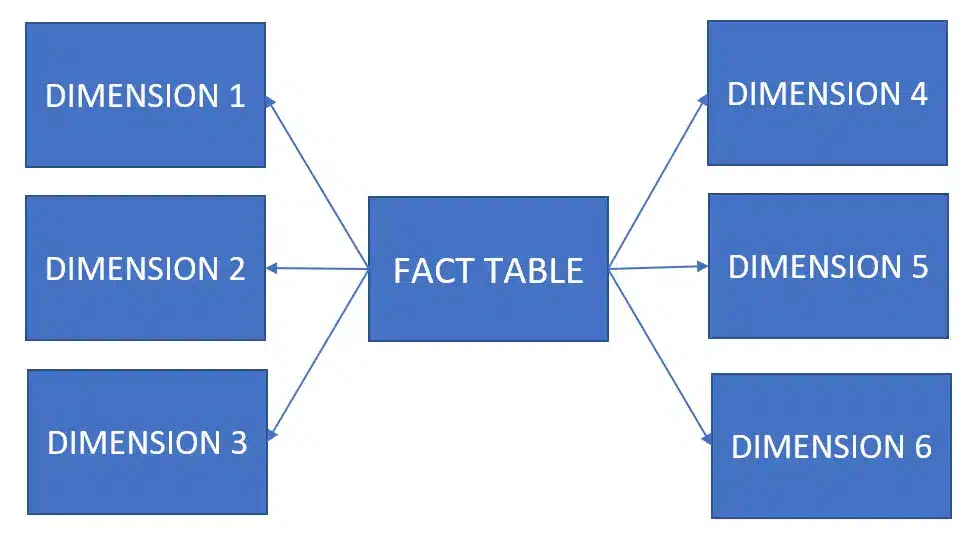
A dimensional data model is commonly used in data warehouse and business intelligence to model and organize data for analytical reporting and decision making. It focuses on creating a structure optimized for querying and analysis rather than transactional processing. In a dimensional data model, data is organized into dimensions and facts.
Dimensions
Dimensions represent the descriptive characteristics of the data. They provide the context in which the facts are analyzed. Dimensions contain attributes that help categorize and describe the data. For example, in a sales dataset, dimensions could include:
Time Dimension: Date, Month, Quarter, Year
Product Dimension: Product Name, Category, Brand
Location Dimension: Country, City, Store
Dimensions allow you to slice and dice the data along various criteria, enabling a deeper understanding of the facts from different perspectives.
Facts
Facts, also referred to as measures, are the quantitative values or metrics that provide meaningful insights for the business. In a sales dataset, examples of facts could include:
Sales revenue
Units sold
Profit margin
Discount percentage
Facts represent the key metrics that you want to analyze, compare, or aggregate to gain business insights.
Dimensions and Facts work in conjunction with each other to facilitate data analytics, facilitating query performance.
Frequently Asked Questions (FAQ)
What is data modeling in databases?
Data modeling in databases refers to designing logical and physical representations of data structures to support efficient storage, access, and analysis. It outlines how data entities relate to one another and helps ensure quality and consistency across systems.
What are the three types of data models?
Conceptual – high-level structure for stakeholder understanding
Logical – detailed structure without concern for technology
Physical – technical implementation inside a specific DBMS
Who creates data models?
Data architects, database administrators (DBAs), and business analysts typically collaborate to create data models depending on project scope and technical complexity.
Need Expert Support?
Whether you’re modernizing your data warehouse or launching a new product, our consultants can help you build scalable, future-ready data models. Talk to a Data Sleek expert