I subscribe to Reddit and a few channels related to data engineering, Snowflake Computing, and others. There are many discussions about how Snowflake is expensive and that there are better solutions out there, like Databrick, Redshift, or even MS Synapse.
At Data-Sleek, Snowflake cost optimization is critical for our clients. We emphasize the importance of Snowflake cost optimization by leveraging the necessary tools to monitor Snowflake resources and implement optimized data architecture to keep costs low.
Snowflake Data Warehouse: How does it work?
Understanding the Cloud Data Warehouse model
Snowflake uses a cloud-based data warehouse model, leveraging hardware elasticity from Cloud providers like AWS, Google, and Azure and a pay-as-you-go pricing structure that scales storage and compute independently.
Unlike traditional on-premise databases, Snowflake does not need to be provisioned with hardware or instance size. Because it separates compute from storage, you can scale each separately. You could need large storage and a few queries per month, which would cost you close to the same as AWS S3 storage.
Or you could have small storage need but lots of queries, which would cost if you don’t manage the compute unit properly. Or you could have both (large storage and lots of requests per month).
Snowflake offers elasticity and performance based on business needs.
Snowflake cost optimization is essential to ensure that you are only paying for the resources you truly need. Implementing effective strategies for Snowflake cost optimization can lead to significant savings in data management.
Understanding this model is key to cost optimization since costs are directly linked to usage patterns.
Implementing Snowflake’s unique architecture for cost optimization
Snowflake architecture allows for dynamic scaling and auto-suspend capabilities, which means you only pay for what you use. Businesses can optimize performance by strategically configuring virtual warehouses and leveraging workload isolation, including statement timeout, without incurring unnecessary expenses.
A virtual warehouse is also referred to as a “computing unit”, a computing size that allows you to handle requests (queries). The bigger the computing unit, the faster the query will run and the larger the dataset it can handle, but the more credits it will consume per hour.
When creating a new warehouse unit, the first thing to do is to make sure the auto-suspend is set to 60 seconds.
Snowflake utilizes per-second billing (with a 60-second minimum each time the warehouse starts), so warehouses are billed only for the credits they actually consume.
The total number of credits billed depends on how long the warehouse runs continuously. For comparison purposes, the following table shows the billing totals for three different sizes of warehouses based on their running time (totals rounded to the nearest 1000th of a credit):

Leveraging Snowflake’s features for automatic scaling and resource optimization
To maximize cost efficiency, organizations should take advantage of auto-scaling and multi-cluster warehouses.
Auto-scaling dynamically adjusts the number of compute nodes based on demand, reducing waste during low-traffic periods. This can be done directly in SQL. Let’s suppose you need to run multiple SQL queries: one to load a large amount of data, another one to join the data and create a stored proc, and another one to summarize the data. Within your SQL code, you could use :
“use warehouse <warehouse_name>; copy data …. then use warehouse
use <smaller_warehouse_name> ; to run the rest.
As you can see the usage or larger or smaller warehouse unit are dynamic and instant. (You do need to create these warehouse unit in advance and grant proper permissions).
To achieve optimal Snowflake cost optimization, organizations should regularly review their usage patterns and adjust their configurations accordingly. This proactive approach to Snowflake cost optimization helps in maximizing efficiency.
Snowflake also provides query caching, which helps optimize resource utilization by retrieving previously executed query results instead of re-running compute-intensive operations. If the same queries run on multiple tables, it will use the caching layer. This is useful for reporting (when plugging dashboards such as Tableau, PowerBI), that are used by many users.
Is Snowflake cost-effective?
Snowflake cost optimization can significantly impact your overall cloud expenditure. By understanding your usage and adjusting virtual warehouse sizes, you can enhance your Snowflake cost optimization efforts.
Right-sizing Virtual Warehouses for Efficiency
Implementing Snowflake cost optimization strategies ensures that you are not overspending and are maximizing the value of your data warehouse investments.
For effective Snowflake cost optimization, consider utilizing Snowflake’s query caching feature, which can greatly reduce the resources required for repeated queries.
Selecting the correct virtual warehouse size is an essential factor for optimal warehouse size selection and minimizing costs. As seen earlier, Snowflake offers multiple warehouse sizes ranging from X-Small to 6X-Large, with compute costs increasing exponentially with size.
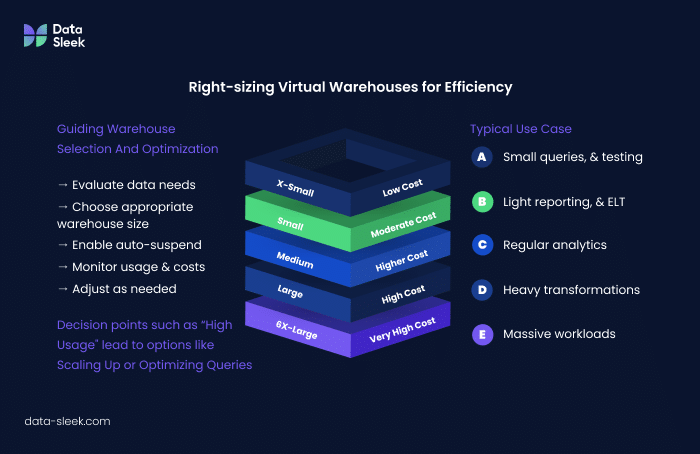
At Data-Sleek, we properly set up the different warehouse units for the different purposes they will serve. We usually create one warehouse unit for loading data, another one to transform the data, one for reporting, and one for the data engineer. This lets us quickly see where most of the credits are spent and act accordingly.
Employing Auto-Suspend and Auto-Resume Wisely
Selecting the correct virtual warehouse size is an essential factor for optimal warehouse size selection and minimizing costs. As seen earlier, Snowflake offers multiple warehouse sizes ranging from X-Small to 6X-Large, with compute costs increasing exponentially with size.
Snowflake costs: how the model works
Factors that contribute to Snowflake costs
Understanding the pricing model of Snowflake is crucial for successful Snowflake cost optimization. By knowing how costs are structured, you can make informed decisions that lead to better financial outcomes.
Snowflake pricing is influenced by three primary factors: storage pricing, compute, and data transfer.
Storage is inexpensive but grows over time if data is not managed correctly across various regions. Usually, it’s about the same as the cost of AWS S3 storage. Snowflake compresses data, so some savings could be made there, too.
Implementing Snowflake cost optimization strategies can transform your data management approach, enabling organizations to scale efficiently while minimizing costs.
Compute costs, determined by the virtual warehouse size and execution duration, can be optimized through efficient query execution. The best is to start with the smallest unit and scale from there. It’s essential to also look at the data architecture. Can the data be “pre-processed” with Spark, for example, instead of having Snowflake do it? These are the types of questions to ask a data architect when implementing a data warehouse solution.
Data transfer fees are minimal but should be considered for cross-region data movement. Will you be exporting data out of Snowflake? How large will the dataset be? How frequently?
Understanding the pricing model of Snowflake
Snowflake pricing is influenced by three primary factors: storage pricing, , compute, and data transfer.
The pay-as-you-go structure of Snowflake’s pricing model allows businesses to effectively manage costs by only paying for the resources they consume. Additionally, the transparent nature of credit usage gives users visibility into their expenses and enables them to optimize their usage for cost-efficiency. Snowflake’s innovative pricing approach has made it a popular choice among organizations looking for a cloud data platform that aligns with their needs and budget requirements.
How to reduce Snowflake costs
Optimizing Storage Through Data Life-cycle Policies
To manage storage costs, organizations should implement data retention policies, using time-travel and fail-safe settings efficiently.
Archiving infrequently accessed data to cheaper storage tiers (e.g., AWS S3 Glacier) and setting retention limits can prevent excessive costs. Snowflake’s automatic data compression also reduces storage consumption without additional effort.
Data Retention Policies
Data retention policies are critical to controlling the growth and cost of data storage. Scripts and other mechanisms can automate this process. Also once the raw data has been processed, it is possible to archive it in Glacier for some cases (especially for real-time analytics).
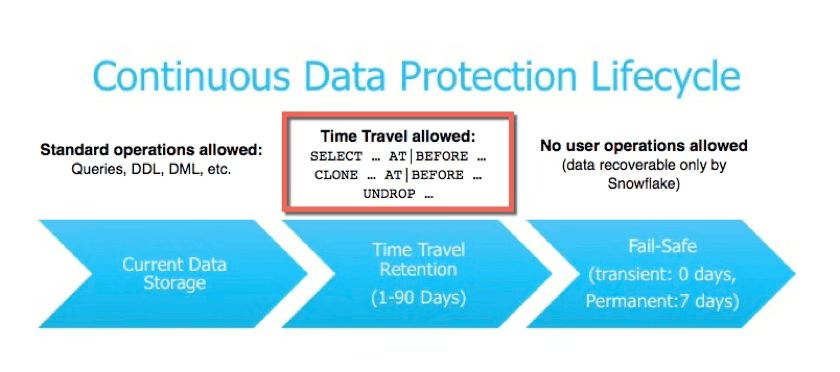
Snowflake time-travel
Snowflake time travel offers key benefits, including data recovery, historical analysis, compliance, and auditing support.
Snowflake Time Travel enables accessing historical data (i.e., data that has been changed or deleted) at any point within a defined period. It serves as a powerful tool for performing the following tasks:
- Restoring data-related objects (tables, schemas, and databases) that might have been accidentally or intentionally deleted.
- Duplicating and backing up data from key points in the past.
- Analyzing data usage/manipulation over specified periods.
Leveraging Caching to Minimize Compute Time
Snowflake caches query results at multiple levels, reducing redundant computations. By leveraging query result caching, metadata caching, and local disk caching, organizations can dramatically decrease execution times and computing expenses. Optimizing SQL queries to reuse cached results further enhances efficiency.
Snowflake Query Result Caching
Benefit: If an identical query is run again within this timeframe (by the same user and role), Snowflake retrieves the result from the cache instead of re-computing the query. Such extended durations can be beneficial for optimizing query performance.
How to Optimize:
- Avoid unnecessary variations in query syntax (e.g., trailing spaces, capitalization differences).
- Use parameterized queries instead of dynamically constructing SQL queries that change frequently.
- Encourage users to reuse previous query results instead of executing similar queries multiple times.
Snowflake Metadata Caching
Snowflake caches metadata and query execution plans to avoid repetitive table scans.
Benefit: Faster metadata retrieval, reducing unnecessary compute costs for operations like SHOW TABLES or DESCRIBE TABLE.
How to Optimize:
- Use INFORMATION_SCHEMA wisely: Avoid excessive metadata queries on large datasets.
- Use efficient query structures: Keep queries structured in a way that allows Snowflake to recognize and reuse metadata.
Snowflake Local Disk Caching
When a virtual warehouse (compute cluster) is running, Snowflake caches data on local SSD storage for fast access.
Benefit: Reduces the need for repeated data retrieval from cloud storage, speeding up queries and lowering compute costs.
How to Optimize:
- Keep warehouses warm when running frequent queries to maintain cache efficiency.
- Group related queries together to take advantage of a warm local cache before suspending a warehouse.
- Avoid stopping and restarting warehouses frequently, as this clears the cache.
Leverage Materialized Views for Performance Boost
Materialized views store precomputed query results, allowing Snowflake to reuse them instead of recomputing.
Benefit: Faster query performance and lower compute usage, especially for frequent aggregations and joins.
How to Optimize:
- Use materialized views for frequent and complex queries with costly joins.
- Be mindful of automatic refresh costs—optimize refresh schedules for cost efficiency.
Snowflake Clustering Keys
Using Clustering Keys helps Snowflake physically organize data with table clustering, reducing the number of scanned rows for queries.
Benefit: Minimizes unnecessary data scans, lowering compute costs.
How to Optimize:
- Choose clustering keys based on frequent filtering columns (DATE, CUSTOMER_ID, etc.).
- Avoid excessive clustering on small tables—it is more beneficial for large tables.
Caching Temporary Tables for Repetitive Calculations
Store aggregated or processed data in temporary tables or transient tables for batch jobs.
Benefit: Prevents re-running expensive computations in complex queries.
How to Optimize:
- Store aggregated or processed data in temporary tables or transient tables for batch jobs.
- Drop temporary tables when no longer needed to avoid unnecessary storage costs.
Snowflake Query Optimization to Maximize Cache Reuse
Writing queries efficiently increases the chances of hitting existing caches.
Benefit: Minimizes redundant compute work, reducing Snowflake credit consumption.
How to Optimize:
- Avoid SELECT *: Specify only the columns needed.
- Use filters and partitions: Querying smaller data subsets improves performance and reduces scanning.
- Pre-aggregate data where possible: Running computations in advance can limit repetitive, expensive operations.
As you can see, there are many ways to optimize Snowflake cache and thus reduce the usage of compute. We have helped many customers reduce their Snowflake cost by 15, 25, and even 45% by many adjustments.
Streamlining ETL Processes for Lower Costs
Extract, Transform, Load (ETL) operations can quickly become expensive if not optimized. When using Snowflake, it is recommended to use the ELT (Extract, Load, Transform) approach instead. Using this method allows us to load the data in the data warehouse and transform the data later,
Loading data in batches will reduce the cost. Some data architectures might suggest storing the data in S3 first, then loading a full day of data into the data warehouse for transformation. This way, Snowflake runs fewer queries, which then limits the cost.
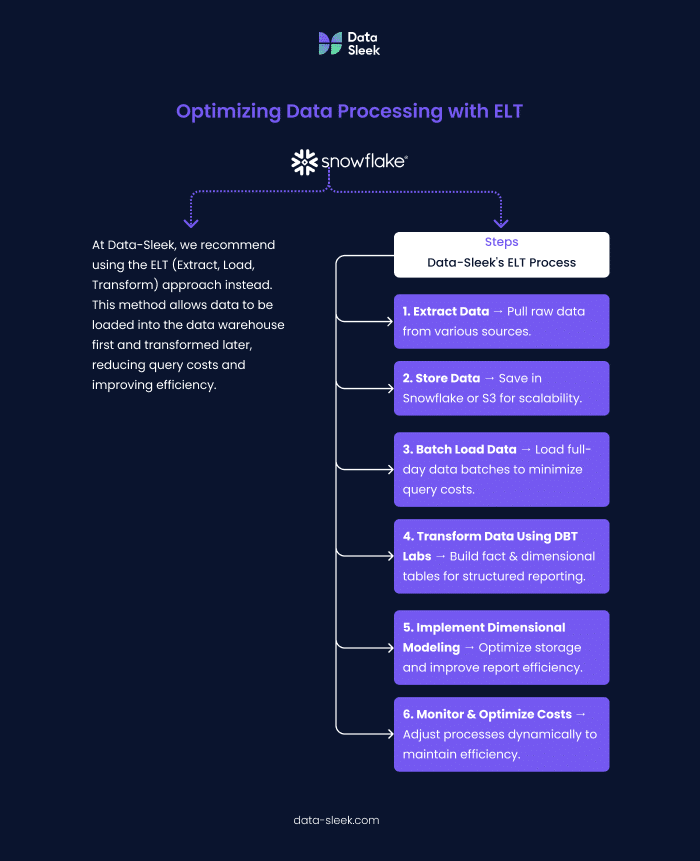
At Data-Sleek, we usually store data in Snowflake directly or S3, then use DBT Labs to transform the data and build fact and dimensional tables. Dimensional modeling is one of the best techniques for storing data in a data warehouse for an efficient, easy-to-use, and scalable reporting solution.
Key metrics to monitor Snowflake costs
Utilizing Snowflake’s Query History for Insights
Snowflake’s Query History provides a valuable resource for understanding usage patterns and optimizing costs. By analyzing query execution times, scanned bytes, and the query frequency of repetitive queries, organizations can identify inefficiencies and tune workloads for better performance. For example, frequent full-table scans or unnecessary large result sets can lead to excessive compute costs, potentially reaching the maximum cost of a single query. Leveraging Query Profiling and Warehouse Load Monitoring, businesses can assess query behavior, pinpoint expensive operations, and implement optimizations such as clustering, partition pruning, or materialized views. Reviewing the query billing details also helps track the compute credits consumed by specific workloads, enabling cost control and more informed decision-making.
Setting Up Alerts for Budget Control
To prevent cost overruns, setting up budget alerts in Snowflake is essential. Snowflake’s Resource Monitors allow administrators to define thresholds for compute credits and receive notifications before exceeding budgeted limits. These monitors can enforce usage caps by suspending virtual warehouses when consumption surpasses predefined thresholds. Additionally, integrating Snowflake’s telemetry with external monitoring tools like AWS CloudWatch, Datadog, or custom dashboards can provide real-time insights into spending trends. Proactive alerting helps finance and engineering teams maintain cost efficiency, ensuring that resource allocation aligns with business priorities while preventing unexpected spikes in cloud expenditure.
Query performance and optimization
Optimizing query performance in Snowflake is crucial for both cost efficiency and data quality. Poorly optimized queries not only slow down data processing but also lead to excessive warehouse usage, increasing costs. Utilizing Query Execution Plans, businesses can identify bottlenecks such as excessive table scans, missing filters, or suboptimal joins. Techniques like clustering keys, pruning unused columns, and leveraging materialized views can significantly provide performance improvements. Additionally, auto-suspend and auto-resume settings for warehouses ensure that compute resources are only used when needed. Regularly monitoring query efficiency through Snowflake’s built-in Performance Dashboard helps maintain fast response times, reduce compute consumption, and improve system reliability.
Conclusion
Snowflake is a powerful and scalable cloud data warehouse, but expenses can quickly spiral out of control without proper cost management.
Understanding its pay-as-you-go model, leveraging auto-scaling, auto-suspend, and query optimization strategies, and implementing effective data lifecycle policies are key to maintaining a cost-efficient Snowflake environment.
Incorporating Snowflake cost optimization into your ETL processes can lead to more efficient data handling and reduced expenses. It’s essential to analyze and refine these processes continually.
Using the ELT approach enhances Snowflake cost optimization by minimizing the number of queries run, thereby reducing the costs associated with data transformations.
At Data-Sleek, we help businesses reduce Snowflake costs by 15%, 25%, or even 45% through smart architecture decisions, workload optimization, and continuous monitoring. Organizations can maximize their return on investment while ensuring high performance by right-sizing virtual warehouses, optimizing storage, leveraging caching, and streamlining ETL processes.
The key to Snowflake cost optimization is not just about reducing expenses but also aligning cloud resources with business needs. With the proper monitoring tools, alerts, and proactive management, Snowflake can remain an efficient, scalable, and cost-effective solution for modern data warehousing.
FAQ:
What are the best practices for Snowflake cost optimization?
Monitoring key metrics is vital for ongoing Snowflake cost optimization. Regular assessments allow for timely adjustments and improvements to resource usage.
Monitor your computing usage. Segment your warehouse unit by main data process : data loading, data transformation, data reporting, and data engineering. Optimize queries, hire a data architect to help implement your data warehouse.
How can I monitor my Snowflake usage effectively?
Snowflake provides Resource Monitors to help track and limit warehouse credit consumption, including the maximum cluster count. You can set thresholds to receive alerts before exceeding budgeted limits. You can also automatically suspend warehouses when usage surpasses a set threshold.
Can auto-scaling reduce costs without impacting performance?
Yes, Snowflake’s multi-cluster warehouses, which automatically scale out (add more clusters), allow for dynamic scaling based on workload demand, ensuring efficient resource usage.
Ultimately, achieving effective Snowflake cost optimization is an ongoing process that requires vigilance and adaptability to changing business needs.
With continued focus on Snowflake cost optimization, organizations can maximize the benefits of their cloud data warehouse while keeping expenses in check.
By emphasizing Snowflake cost optimization, Data-Sleek helps clients achieve greater efficiency and cost savings in their data management strategies.
Thus, the journey toward Snowflake cost optimization is not merely about reducing costs but also about enhancing the overall efficiency of data operations.
Implementing consistent practices centered on Snowflake cost optimization will foster a culture of cost awareness across the organization.
For comprehensive Snowflake cost optimization, organizations must regularly revisit their strategies and ensure that resources align with operational requirements.


