Your organization may not have a clue what Dbt Mesh is. However, you are likely aware of the challenges you’re facing to scaling your organization. Solutions like Dbt Labs have created powerful tools for organizations like yours to take your business to the next level.
Scaling data operations also increases the complexities; it’s more like they both go hand-in-hand. From organizing workflows to securing data integrity, large-scale data platforms need more than simple solutions.
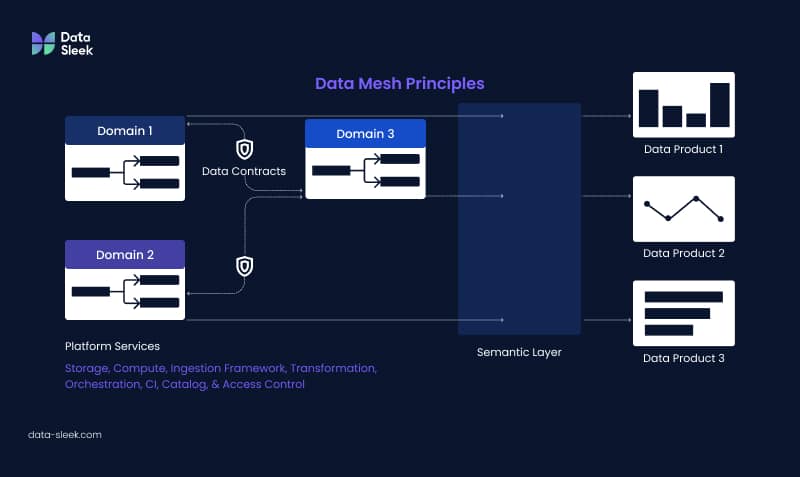
Luckily, Dbt tools simplify these hurdles. At the Coalesce Conference, data experts shared how Dbt Lab’s best practices make scaling seamless by further smoothing the data transformation process.
Moreover, the Dbt models help data teams stay organized, agile, and efficient. In this blog, we’ll explain how Dbt Mesh can optimize workflow, maintain high data quality, and provide a set of guarantees for reliable performance.
👉 Looking to streamline your data transformation with Dbt? Our expert consultants can help you implement best practices and scale efficiently. Learn more about our Dbt Consulting Services here.
What Is Dbt Mesh?
Dbt Mesh is a powerful approach within Dbt Labs (or an extension of Dbt Cloud) that enables seamless collaboration and flexibility across multiple data projects. Connecting various Dbt Labs projects allows teams to manage complex data ecosystems with ease, ensuring that models across different projects work cohesively.
This setup is ideal for organizations with large-scale data operations, as it enhances scalability while maintaining strong governance. With Dbt Mesh, different teams can enjoy a unified workflow, helping them align on shared resources, avoid bottlenecks, and streamline data processes as projects and teams expand.
What Features of Dbt Mesh Simplifies the Management of Data Systems
Dbt Mesh is designed to simplify and organize data systems, making it easier for teams to manage data models, enforce quality, and streamline collaboration.
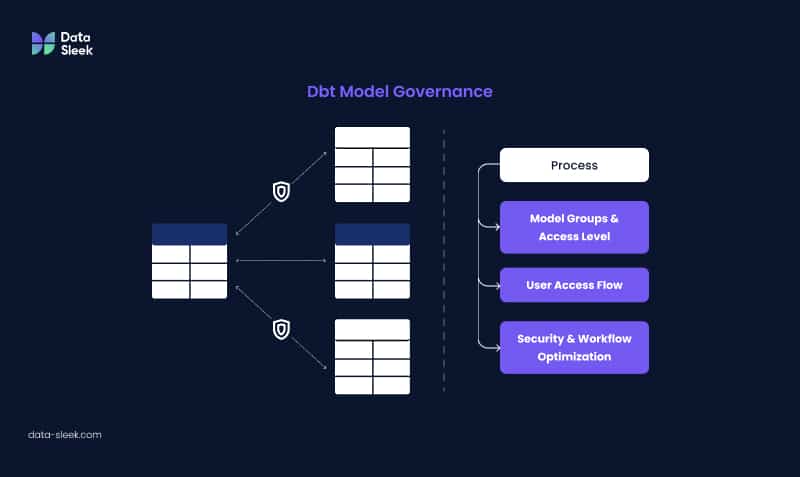
Here’s how each feature contributes to efficient data management:
1. Dbt Model Governance
In Dbt, model groups are like folders for organizing data models based on how often they’re used or their purpose. Think of them as buckets that categorize models, whether they’re used hourly, daily, or monthly. This structure not only organizes workflows but also makes it easy to know which models are ready for use and which are still being tested.
Access Levels for Models:
- Protected: Default access, ideal for models still being reviewed or checked.
- Public or Protected: For models that are polished and ready for team-wide use.
- Private: Used for models under development, meaning they’re still being tested and aren’t ready for general use.
Organizing models into these categories helps teams work better together, reduces confusion, and ensures that only finalized models are widely accessible. This way, work-in-progress models don’t interfere with stable, production-ready models.
Moreover, these access levels add an extra layer of protection as they ensure that only approved people can change important data models.
2. Dbt Model Contracts
One of Dbt’s standout features is model contracts, which ensure every model aligns with set standards before it’s put to work. It enforces key details, such as column names, data types, and specific conditions in their pipelines to prevent errors.
How It Works:
- Preflight Checks:
Before running a process, Dbt confirms the model has the right data structure. This stops issues from happening in the production environment. These checks keep data pipelines consistent and standardized.
Using automation and continuous integration, preflight checks immediately improve data quality. This creates a strong starting point for smooth workflows and timely delivery of data products.
- DDL Enforcement:
Managing changes in the database structure is very important for keeping a healthy data warehouse. Dbt’s DDL enforcement feature helps control how these changes happen.
This feature keeps the planned schema and data types consistent. It helps avoid differences between the models and the actual database. This is especially helpful when many teams work on the same data warehouse. It ensures uniformity and stops accidental changes to the schema.
When you clearly define what the data should look like, its structure, and how it relates to other data, you build a strong base for reliable analytics and reporting. By finding data issues early in the transformation steps, you increase data accuracy, which leads to better business decisions.
3. Multi-Project Collaboration

When a company grows, so does its data team, and often multiple teams work on different projects. Dbt supports multi-project collaboration by letting teams work independently while still aligning efforts through shared resources and other dependencies. It allows them to share models, macros, and other Dbt tools.
This setup allows teams to move quickly without bottlenecks. Cross-team collaboration becomes easier, ensuring that each team’s work complements the others, preventing workflow slowdowns, and making the data pipeline more efficient.
4. Dbt Model Versioning
Model versioning in Dbt is like version control for data models, allowing data software engineering principles to update and replace models without disrupting workflows. It keeps a clear record of every change made to models, macros, and other Dbt parts.
How It Works:
- Track Changes Over Time: Teams can monitor what’s been updated, when, and why. Ensuring that all stakeholders are aware of the latest model version and its associated changes.
- Multiple Versions for Testing: For instance, teams can safely test a breaking change by running a new model alongside the current one before fully transitioning.
- Protecting Downstream Workflows: By managing multiple versions, Dbt minimizes disruptions to other teams relying on specific models.
This approach allows smooth updates and ensures that the entire (CI/CD) pipelines continue to work effectively, even during model migrations or upgrades.
5. Dbt Mesh for Flexibility
As data needs grow, projects often expand to include multiple teams, tools, and goals. Dbt Mesh addresses the challenges of lack of standardization and ensures consistency across different teams through its structured approach and data governance capabilities.
Dbt’s configuration options help connect datasets seamlessly, allowing them to work as one cohesive system while avoiding redundant tasks and conflicts. This powerful integration capability helps teams leverage data across multiple dashboards, metrics, and APIs, ensuring stakeholders can access the most accurate and timely insights.
Achieve Scalable Data Systems with Data-Sleek Today!
Dbt scaling makes data operations possible, effective, and manageable. By using tools like model groups, contracts, and versioning, companies can streamline their data processes, reduce errors, and foster better teamwork.
At Data-Sleek®, we specialize in helping even the largest teams harness the full power of Dbt to create reliable, scalable data systems to meet today’s needs while being ready for tomorrow’s growth.
Ready to start your company data transformation? Contact us today, and let’s develop a data strategy that scales with you.

Frequently Asked Questions
What Makes DBT Different from Traditional ETL Tools?
DBT is different from traditional ETL tools because it only focuses on the transformation part in your data warehouse. It uses SQL and a code-based method. This makes data transformations more efficient, easier to maintain, and allows for better scalability.
How Can DBT Improve Data Quality in My Projects?
DBT Cloud has many features that improve data quality in your projects. It includes testing tools that come built-in. You can also use model contracts to validate your data. Plus, you can set up your own rules for data quality. This will help keep your data accurate and consistent.
Can DBT Scale with My Growing Data Needs?
Yes, DBT is made for scalable data transformations. It doesn’t matter if your data is in a small database or a big data warehouse. DBT can handle your growth as the amount and complexity of your data rise.
What Are the First Steps to Adopting DBT in My Organization?
Start by picking a project or team to use DBT.
Teach team members the basics of DBT.
Slowly include it in your workflow using a structured approach.
Where Can I Find Additional DBT Learning Resources?
DBT Labs offers a lot of helpful documents, guides, and a lively forum for its users. You can also discover online courses and DBT learning tools available from different educational websites and groups.
How to Handle Dynamic Data Sources in DBT?
DBT models can easily work with changing data sources. You can set up your models to adjust to new schemas or data structures. This way, you stay flexible and can add data from sources that keep changing.
Tips for Optimizing DBT Performance in Large Datasets
To make DBT work better with large datasets, you should focus on using efficient SQL queries. Use the right data materializations, and take advantage of DBT’s incremental builds. This way, you will only process the data that has changed.


