Imagine unlocking the full potential of your data transformation process while reducing the time and effort required to maintain your data pipeline.
This dream can become a reality with a dbt tool (Data Build Tool), a powerful open-source command-line tool designed to simplify the transformation of your data pipelines. We’ll explore the ins and outs of DBT tools, its key features, and how it can bring efficiency, quality, and collaboration to your data projects.
DBT Tool (Data Build Tool) Key Takeaways
- dbt is an open-source tool that enables efficient data transformation and optimization of ETL processes.
- It provides comprehensive features such as modularity, version control, testing, documentation & SQL-based data modeling to ensure accurate & reliable data.
- Learning resources are available through official documentation and various online platforms to facilitate the understanding of its capabilities.
Understanding DBT Tools: Data Build Tool Explained

In the dynamic data field, this tool distinguishes itself as an innovative solution to the challenges confronting data teams. It allows data analysts and engineers to manipulate data per their requirements, simplifying the entire analytics engineering workflow.
DBT’s unique features provide several advantages, including automated documentation, transparency, and insight into the data pipeline via lineage graphs that optimize the company’s business analytics. Dbt supports the essential components of the entire analytics engineering workflow through SQL-based data modeling, Jinja templating, version control, and CI/CD integration.
At its core, it comprises a compiler and a database runner designed to assist data teams in constructing, verifying, and sustaining their data infrastructure.
What is a DBT tool?
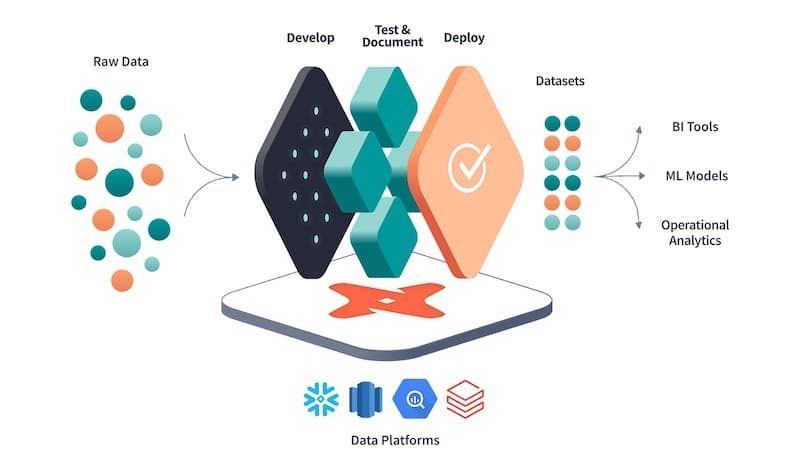
This open-source tool is a multifaceted tool created to assist organizations in constructing, testing, and maintaining their data infrastructure. It enables the creation of data models using SQL and generates optimized SQL code for efficient execution.
DBT’s core functionality revolves around creating and validating data models essential to maintaining high data quality. Data analysts and analyst engineers primarily use it to create models encapsulating fundamental business logic.
It streamlines the transformation of raw data by analytics engineering best practices, producing boilerplate code.
For example, a data analyst can easily create a data model that computes the total revenue for a specific timeframe by combining tables containing sales data and product details. This reusable data model can be incorporated into another data warehouse project by other data analysts.
How does DBT Tool (Data Build Tool) work?
Dbt’s strength lies in its ability to:
- Transform user-written code into raw SQL and run it against a data warehouse
- Support various materialization strategies
- Utilize SQL and Jinja
- Provide pre-built testing capabilities to ensure data quality and integrity.
Modularity is another key aspect of dbt, as it allows users to reference other data models within their Jinja context using the Ref() function. This feature simplifies updating and maintaining data transformations, making dbt an ideal solution for organizations seeking to optimize their data pipeline.
The Benefits of Using a DBT Tool (Data Build Tool) for Data Transformation

Using DBT solutions provide organizations with a host of advantages, including:
- Productivity enhancement across data teams
- Reproducible transformations
- Collaboration
- Scalability
- Ensuring Data Quality
- Flexibility
- Data lineage
- Documentation
The ability to write boilerplate code once and reuse it multiple times minimizes the time spent on coding, improving the efficiency of handling raw data. A simple example of this is the use of reusable functions or modules in a programming language.
Moreover, it enables data control by allowing users to:
- Ensure data validation and verification, promoting the reliability and precision of the data
- Utilize dbt for collaboration and reusability, streamlining the process of transforming data
- Facilitate collaboration on data projects
- Enable code reuse across multiple projects
Utilizing dbt cloud offers a more efficient and effective approach. Because the development is done in a browser, anyone can collaborate and verify the work anywhere.
Improved Efficiency
Dbt’s unified platform offers the following features:
- Users can write and execute their code in a single language.
- It provides a library of pre-built data transformation functions that streamline the data transformation.
- This simplification enhances efficiency and makes data transformation user-friendly for those with data analyst skills.
By automating the ETL process and streamlining the management and maintenance of data pipelines, dbt offers a significant improvement in efficiency compared to other tools.
Enhanced Data Quality
Data integrity and quality are paramount for accuracy, reliability, and consistency. dbt tackles these issues with its wide-ranging prebuilt and customizable testing capabilities, ensuring control over the entire data transformation process.
Collaboration and Reusability
One of dbt’s greatest strengths is its ability to facilitate collaboration and reusability. By providing modular code and sharing libraries of commonly used macros and models, dbt enables teams to work together more efficiently and effectively.
Key Features of a DBT Tool
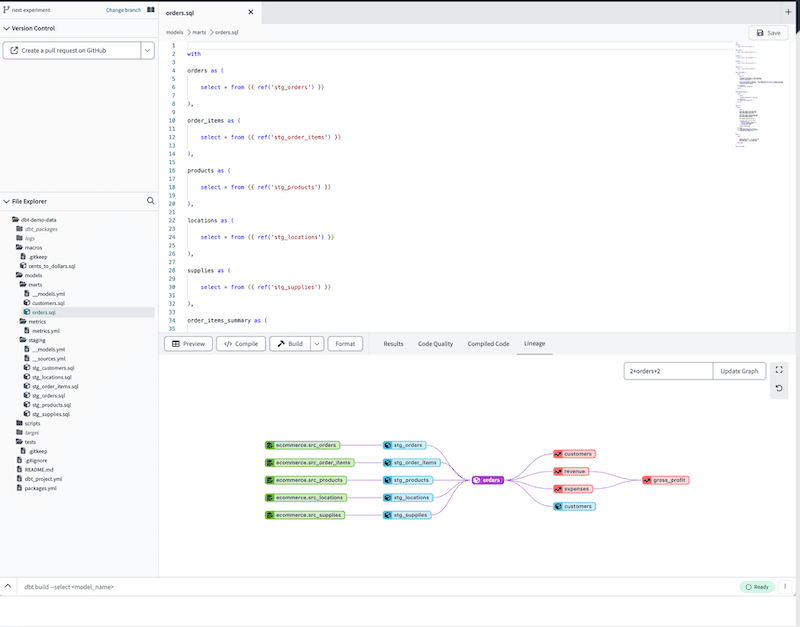
dbt offers a range of key features that make it an invaluable tool for data transformation and pipeline building, including:
- Modularity
- Testing
- Documentation
- Incremental builds
- Data lineage
- Collaboration
- Extensibility
Dbt-core and dbt cloud, SQL-based data modeling, Jinja templating, version control, and CI/CD integration, dbt equips users with powerful capabilities to manage and maintain their data pipeline efficiently. This ensures that data models are accurate, reliable, and up-to-date, enabling organizations to make informed, data-driven decisions.
How does DBT simplify the implementation of a modern data warehouse?
Building a data warehouse was traditionally segmented into distinct tasks managed by different teams. ETL (Extract, Transform, Load) engineers handled the heavy lifting of data transformation, while data analysts were tasked with querying and reporting. This siloed approach could result in bottlenecks, limited scalability, and a slower pace of insights. DBT (Data Build Tool) helps simplify and expedite this workflow by bringing modern software engineering practices to data analysts and into the data warehousing environment and, more precisely, bringing data analysts closer to the data engineering role.
- SQL-Focused Workflow: One of DBT’s key features is its SQL-centric approach. Most data professionals are already familiar with SQL, making it easier to use DBT to transform raw data directly within the data warehouse. This negates the need for complex, intermediary ETL processes, streamlining the process of transforming data and accelerating time-to-insight.
- Modularization and Reusability: DBT promotes using modular SQL queries, also known as “models,” which reflect a company’s business logic. These reusable data models speed up the development across different projects and teams.
- Version Control (VC): Like modern software development, DBT integrates seamlessly with VC systems like Git. This means that changes to data transformation logic can be tracked, reviewed, and rolled back if necessary. It adds a layer of accountability and makes it easier to collaborate across teams.
- Data Testing and Validation: DBT plays a key role in maintaining the quality of data, which is critical for any data pipeline. It empowers data analysts to write tests alongside the transformation code, simplifying your data’s quality. These tests are automatically executed during the transformation process, promptly identifying inconsistencies or problems.
- Documentation and Lineage: Understanding data flow through your systems is crucial for debugging issues and compliance. DBT auto-generates documentation, clearly showing data lineage and dependencies within your warehouse. This facilitates easier troubleshooting and ensures that both technical and non-technical stakeholders can understand the data flow.
- CI/CD Integration: Continuous Integration and Continuous Deployment (CI/CD) are standard practices in software engineering that are now being applied to data operations through tools like DBT. These practices allow for automated testing and deployment of changes, making the data pipeline robust and agile.
By integrating software engineering best practices into data transformation tasks, DBT helps to streamline the workflow associated with implementing and maintaining a modern data warehouse.
Talk to an expert about your dbt needs.
Frequently Asked Questions (FAQ)
Is DBT an ETL tool?
No. DBT performs only the Transform portion of ELT. It assumes your data is already in the warehouse and focuses on SQL-based modeling and testing.
Who uses DBT?
Analytics engineers, data analysts, and engineers working with modern data stacks like Snowflake, BigQuery, and Redshift can use DBT effectively. Anyone familiar with SQL can also use it.
What are the top benefits of DBT?
Improved transformation speed, testable SQL models, documentation, data quality, and collaboration across data teams.
Can DBT be used in production pipelines?
Yes, DBT is designed for production environments. Teams often deploy DBT jobs using schedulers like Airflow, Prefect, or DBT Cloud’s built-in job scheduler.
Does DBT support incremental loading?
Yes. DBT offers built-in support for incremental models, allowing you to load only new or changed records instead of rebuilding the entire dataset.






