Introduction
Welcome to Data Sleek’s blog on Snowflake SQL (structured query language) tips! This comprehensive guide will explore essential SQL techniques and best practices to optimize your data manipulation and analysis tasks using Snowflake.
Snowflake is a powerful cloud-based data platform known for its scalability, flexibility, and performance. By leveraging efficient Snowflake SQL commands and techniques, you can unlock the full potential of a Snowflake data warehouse and maximize the value of your data warehouse.
What is Snowflake SQL?
Why are efficient SQL techniques crucial? SQL is the primary language for interacting with databases and utilizing it effectively can significantly impact the speed and accuracy of your queries.
In this blog, we have organized the content into five key sections to provide you with a structured learning experience:
- Useful SQL Queries: Learn about fundamental and advanced SQL commands that form the backbone of data manipulation and analysis tasks.
- Dimensional Modeling: Discover the power of dimensional modeling in Snowflake. We will explore the concepts and benefits of dimensional modeling for data warehousing and reporting and dynamic dimensional modeling for dates.
- Stored Procedures: Dive into the world of stored procedures and their role in Snowflake. We will explore how stored procedures can streamline your data processing tasks and enhance code reusability. You will find examples of Snowflake SQL command and code for creating and executing stored procedures.
- Functions: Discover the power of user-defined functions (UDFs) in Snowflake. UDFs enable you to encapsulate complex logic into reusable code blocks. We will cover different types of functions available in Snowflake, such as scalar and table functions. With practical examples, you will learn how to define and use functions effectively for common data manipulation tasks.
- JSON: Uncover Snowflake’s support for JSON data and its advantages. JSON (JavaScript Object Notation) is a popular data format for semi-structured data. We will explore Snowflake’s capabilities for working with JSON data, including parsing, extracting elements, modifying and transforming data, and combining JSON with structured data. You will find illustrative examples of Snowflake SQL code for handling JSON.
By the end of this blog, you will have a strong foundation in Snowflake SQL and be equipped with practical tips and examples to enhance your data manipulation and analysis workflows.
DDL versus DML
Before we dive deep into SQL queries, it is important to understand the distinction between Data Definition Language (DDL) and Data Manipulation Language (DML) in the context of database operations:
- DDL: Data definition language (DDL) is used to define and merge the structure and schema of the database. DDL commands create, modify, and delete database objects such as tables, views, indexes, and stored procedures. Examples of DDL statements include ‘CREATE TABLE’, ‘ALTER TABLE’, ‘DROP TABLE’, and ‘CREATE PROCEDURE’.
- DML: Data manipulation language (DML) is used to manipulate data within a database. DML operations are responsible for inserting, updating, deleting, and retrieving data from database tables. Examples of DML statements include ‘INSERT INTO’, ‘UPDATE’, ‘DELETE FROM’, and ‘SELECT’.
Now that we have understood the difference between DDL and DML let us dive into basic SQL commands.
Fundamental Snowflake SQL Queries
Mastering essential SQL queries is key to efficiently manipulating and analyzing your data when working with Snowflake. This section will explore basic syntax that will empower you to extract valuable insights from your datasets.
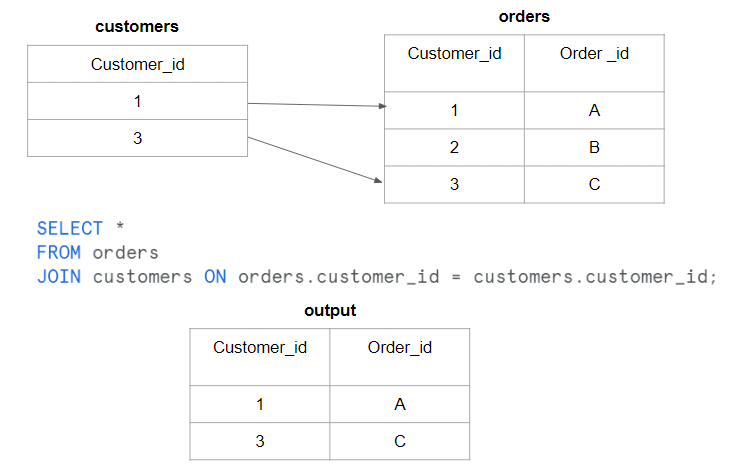
Retrieving Data From Multiple Tables Using JOINS
When dealing with relational databases, it is often necessary to fetch data from multiple tables using joins. Snowflake provides robust capabilities for joining tables efficiently. To optimize this process, consider the following tips:
- Use appropriate join types: Understand the different join types (e.g., inner join, left join, right join, full join) and select the most suitable one based on your data relationships.
- Ensure proper indexing: Identify the columns used in join conditions and create appropriate indexes to speed up the join process.
- Leverage join hints: Snowflake offers join hints that guide the query optimizer. To optimize join performance, experiment with join hints like INNER, LEFT, HASH, MERGE, or BROADCAST.
Aggregating and Grouping Data
Aggregation queries are commonly used to summarize and analyze data across different groups. Snowflake offers powerful aggregation functions such as SUM, AVG, COUNT, MAX, MIN, and more. Consider the following tips to optimize your aggregation queries:
- Use appropriate grouping: Identify the key columns for grouping data and ensure they are included in the GROUP BY clause.
- Minimize the data set: Filter the data before aggregation using WHERE clauses to reduce the volume of data processed.
- Utilize materialized views: Consider creating materialized views to precompute and store the results for frequently executed aggregation queries.

Filtering and Sorting Data
Filtering and sorting data is a common task in data analysis. Snowflake provides various operators and functions to perform these operations efficiently. Consider the following tips:
- Use proper indexing: Identify the columns frequently used in WHERE clauses and create appropriate indexes to speed up the filtering process.
- Leverage predicate pushdown: Snowflake’s optimizer performs predicate pushdown, which pushes filtering operations closer to the data source for improved performance.
- Apply limit clauses: When fetching a subset of data, use the LIMIT clause to restrict the number of rows returned.

Advanced Snowflake SQL Queries
This section will explore advanced SQL command techniques beyond the basics, enabling you to tackle complex data manipulation and analysis tasks in Snowflake. By mastering these advanced SQL tips, you’ll be equipped to handle intricate scenarios and optimize query performance further. Let’s dive in!
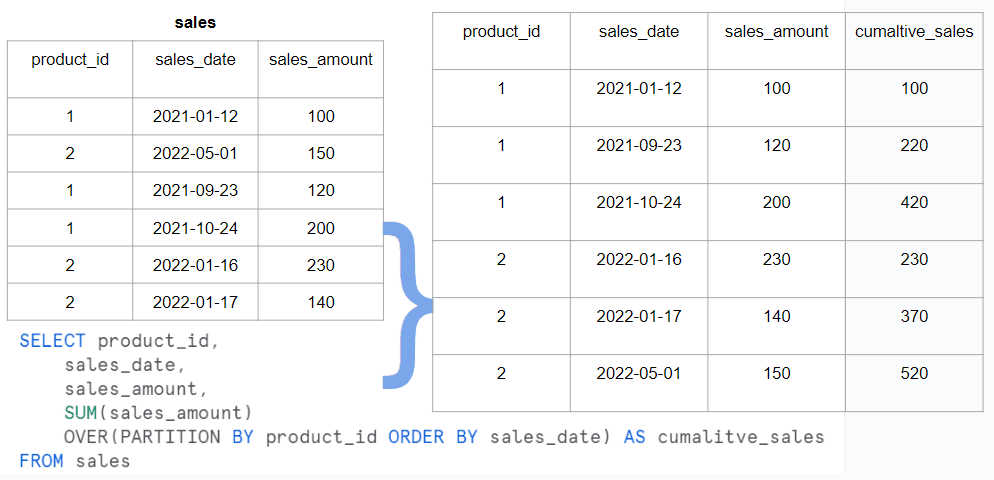
Window Functions
Window functions provide a powerful way to perform calculations and aggregations over a specific set of rows in a query result. They can help solve complex analytical tasks efficiently. Consider the following advanced tips:
- Partitioning data: Use the PARTITION BY clause to divide the data into logical partitions based on specified criteria. This allows you to perform calculations and aggregations within each partition.
- Ordering data: Utilize the ORDER BY clause with window functions to define the desired order of rows within each partition.
- Specifying window frames: Define the range of rows over which the window function operates using the ROWS BETWEEN clause. This allows you to calculate a subset of rows, such as a moving average or cumulative sum.
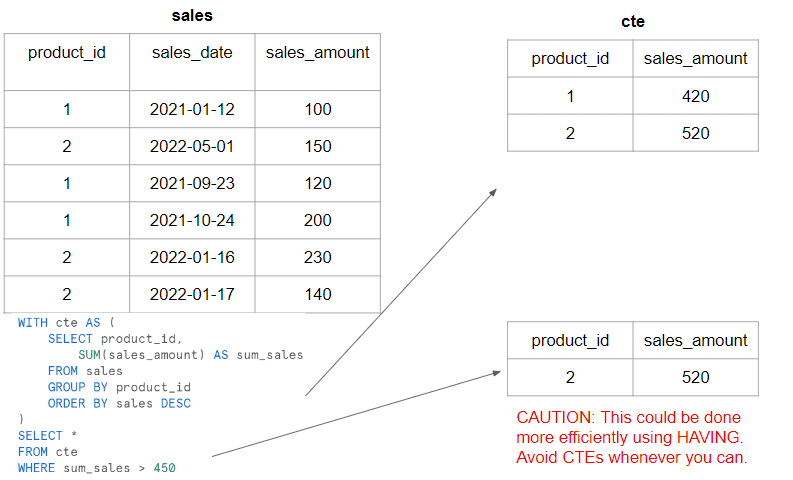
Common Table Expressions (CTEs) for Complex Queries
CTEs provide a way to break down complex queries into smaller, more manageable parts, making them easier to read, maintain, and optimize. Consider the following advanced tips:
- Recursive CTEs: Snowflake supports recursive CTEs, allowing you to traverse hierarchical or graph-like data structures. This is particularly useful for tasks such as organizational hierarchies or network analysis.
- Multiple CTEs: Combine multiple CTEs in a single query to break down complex tasks into smaller, modular steps. This improves query syntax readability and maintainability.
- Use CTEs for data transformation: CTEs can be leveraged to transform data, apply filters, or perform calculations before proceeding to the final query. This enables more granular control over the data manipulation process.
Subqueries for Complex Filtering
Subqueries allow you to nest queries within the main query to perform complex filtering and data retrieval operations. Consider the following advanced tips:
- Correlated subqueries: Use correlated subqueries to reference values from the outer query within the subquery, allowing for more dynamic and context-aware filtering.
- Subqueries in SELECT and FROM clauses: Besides using subqueries in WHERE clauses, leverage subqueries in a SELECT statement or a FROM clause to perform calculations, derive columns, or create temporary result sets.
- Optimize subqueries: Ensure that subqueries are written efficiently by minimizing their impact on query performance. Use proper indexing and evaluate the need for subqueries by considering alternative query structures.

Dimensional Modeling
This section will explore the world of dimensional modeling and its relevance in Snowflake. Dimensional modeling is a popular data warehousing and reporting technique to organize data for efficient analysis. We will delve into the concepts, benefits, and best practices of dimensional modeling in Snowflake, providing you with the knowledge to design effective dimensional models for your data.
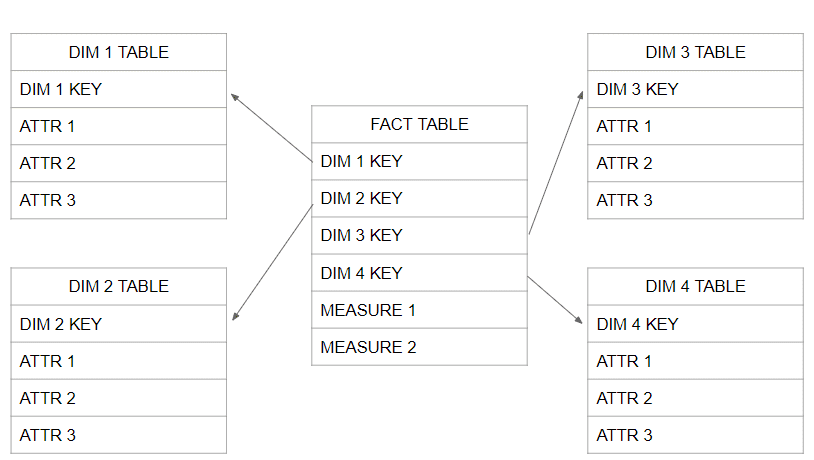
Dimensional modeling is a design approach to structuring data for optimal querying and analysis. It involves organizing data into two primary types of tables: fact tables and dimension tables.
- Fact tables: Fact tables store measurable business data, often called metrics or measures. Examples include sales amounts, quantities, or counts. Fact tables contain foreign keys to dimension tables and provide the context for analyzing the measures.
- Dimension tables: Dimension tables contain descriptive attributes that provide context and help categorize the data in the fact tables. Dimensions represent the different perspectives or viewpoints of the business, such as time, location, product, or customer. Dimension tables are typically smaller in size compared to fact tables.
Dimensional modeling offers several benefits when working with Snowflake’s cloud-based data platform:
- Simplified query design: Dimensional models provide a user-friendly structure that aligns with how users think about the business. This simplifies query design and makes it easier to express complex analytical questions.
- Improved query performance: Snowflake’s architecture is optimized for querying structured data, which aligns well with dimensional models. Using dimension tables and appropriate indexing enhances query performance, allowing faster data retrieval and analysis.
- Enhanced data governance: Dimensional modeling promotes consistency and standardization in data definitions and hierarchies. This improves data governance practices and ensures the accuracy and integrity of the analyzed data.
When designing dimensional models in Snowflake, consider the following tips and best practices:
- Choose appropriate schema design: Snowflake supports both star and snowflake schemas. In a star schema, dimension tables are directly connected to a central fact table. In a snowflake schema, dimension tables are further normalized into sub-tables. Assess your data requirements and query patterns for the most suitable schema design.
- Utilize surrogate keys: Surrogate keys are artificially generated unique identifiers assigned to each record in a dimension table. They facilitate efficient joins and simplify data management. Snowflake automatically generates surrogate keys using the SEQUENCE object, ensuring the uniqueness of dimension records.
- Incorporate natural keys: These are business-defined identifiers uniquely identifying dimension records. Consider including natural keys in your dimensional models to maintain data integrity and enable easy integration with external systems.
- Implement slowly changing dimensions (SCD): SCD techniques allow tracking changes in dimension attributes over time. Snowflake provides temporal table functionality that simplifies the implementation of SCD types, such as Type 1 (overwrite), Type 2 (historical versioning), and Type 3 (partial update).
Dynamic Dimensional Modeling with Example from Data Sleek
Dynamic dimensional modeling refers to designing a dimension that can adapt to changing requirements and accommodate various levels of granularity. The date dimension involves creating a flexible structure that supports hierarchies like year, quarter, month, day, and even custom groupings, like tracking holidays.
Dynamic date dimensional modeling provides several advantages for data analysis and reporting in Snowflake:
- Flexible date aggregations: With a dynamic date dimension, you can easily perform aggregations at different levels of granularity without the need for separate columns for each level. This flexibility allows for more comprehensive and insightful analysis.
- Easy time-based comparisons: Dynamic date dimensions enable effortless comparisons between different periods, such as year-over-year or quarter-over-quarter. This capability simplifies trend analysis and supports better decision-making.
- Scalability and adaptability: By designing a dynamic date dimension, you future-proof your data model, making it easier to accommodate changes in business requirements, other time hierarchies, or custom date groupings.
Check out Data Sleek’s open-source code for dynamic dimensional modeling for the date dimension.
Customer and Product Dimensions
Are you interested in developing other dynamic dimensions like product, customer, pricing, and more? Do not hesitate to contact us now!
Stored Procedures in Snowflake SQL
This section will explore the world of stored procedures in Snowflake. Stored procedures offer a powerful way to encapsulate complex logic and perform data manipulation tasks within the Snowflake environment. We will discuss the benefits of using stored procedures, provide illustrative examples of Snowflake SQL code for creating and executing them, and offer tips for creating efficient and maintainable stored procedures.
Stored procedures are pre-compiled blocks of code stored and executed within the Snowflake database. They allow you to encapsulate business logic, data transformations, and complex queries into reusable units. Stored procedures offer several benefits:
- Code encapsulation: You can create modular and reusable logic units by encapsulating code within a stored procedure. This enhances code organization and maintainability.
- Improved performance: Stored procedures can execute multiple SQL statements as a single unit, reducing network round-trips and optimizing query performance.
- Enhanced security: Stored procedures allow you to control data access and enforce security measures by granting appropriate permissions to the procedure while restricting direct access to underlying tables.
- Transaction management: You can manage transactions explicitly within stored procedures, ensuring data consistency and integrity.
Snowflake SQL Example for Creating and Executing Stored Procedures
To create a stored procedure in Snowflake, you can use the JavaScript-based procedural language called JavaScript Stored Procedures (JSP). Here’s an example of Snowflake SQL code for creating and executing a simple stored procedure:
— Create a stored procedure
CREATE OR REPLACE PROCEDURE calculate_total_sales()
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
AS
$$
var totalSales = 0;
var stmt = snowflake.createStatement({sqlText: “SELECT SUM(sales_amount) FROM sales;”});
var result = stmt.execute();
if (result.next()) {
totalSales = result.getColumnValue(1);
}
return “Total sales amount: ” + totalSales;
$$;
— Execute the stored procedure
CALL calculate_total_sales();
Functions
In this section, we will explore user-defined functions (UDFs) in Snowflake, which provide a powerful way to extend the functionality of Snowflake SQL queries and perform complex calculations and transformations. We will discuss the concept of UDFs, provide practical examples of Snowflake SQL code for defining and using functions, and offer tips for creating and utilizing functions effectively.
User-defined functions (UDFs) in Snowflake allow you to define custom functions that can be used within SQL queries. UDFs enable you to encapsulate complex logic, calculations, and transformations into reusable units, enhancing code modularity and readability.
Snowflake supports various types of UDFs, including scalar functions, table functions, and row functions:
- Scalar functions: Scalar functions operate on a single input value and return a single output value. They can be used for mathematical calculations, string manipulations, date manipulations, and more.
- Table functions: Table functions accept input parameters and return a result set that can be used in SQL queries. They are useful for generating result sets based on complex logic or retrieving data from external sources.
- Row functions: Row functions operate on individual rows of a table or result set. They allow you to perform calculations or transformations on a row-by-row basis.
Let’s take a look at some practical examples of Snowflake SQL commands for defining and using user-defined functions:
— Creating a scalar function
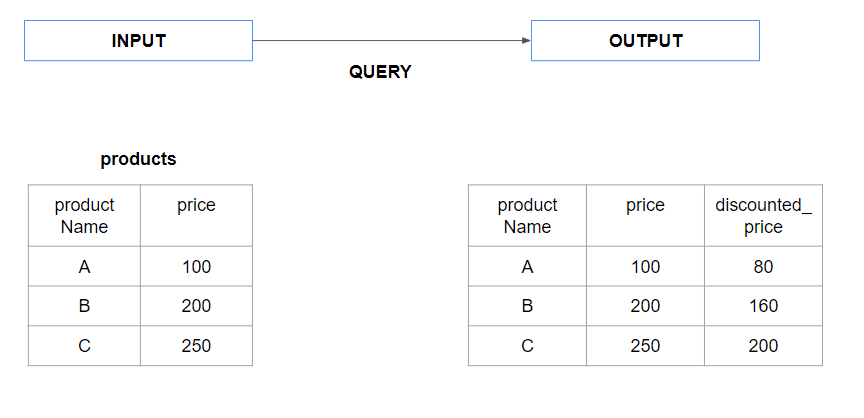
CREATE OR REPLACE FUNCTION calculate_discounted_price(price FLOAT, discount FLOAT) RETURNS FLOAT LANGUAGE SQL AS ' SELECT price * (1 - discount); ';
— Using the scalar function in a query syntax
SELECT product_name, price, calculate_discounted_price(price, 0.2) AS discounted_price FROM products;
— Creating a table function
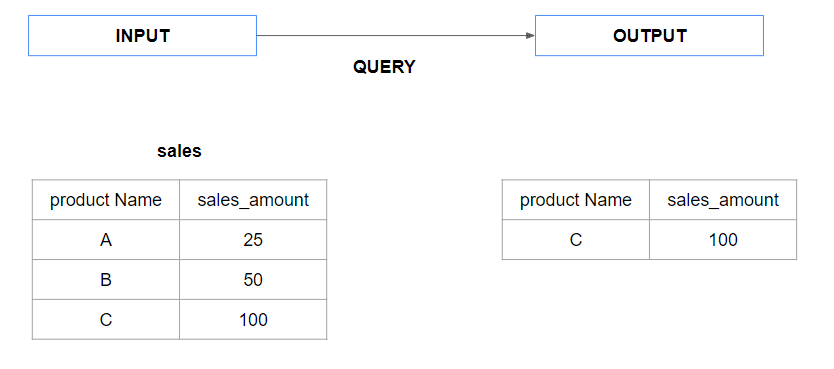
CREATE OR REPLACE TABLE FUNCTION get_high_sales_products(threshold FLOAT) RETURNS TABLE (product_name VARCHAR, sales_amount FLOAT) LANGUAGE SQL AS ' SELECT product_name, sales_amount FROM sales WHERE sales_amount > threshold; ';
— Using the table function in a query
SELECT * FROM TABLE(get_high_sales_products(50));
Tips for Creating and Utilizing Functions
- Design efficient UDFs: Optimize the logic of your UDFs to ensure they perform calculations and transformations efficiently.
- Use appropriate SQL constructs, indexing strategies, and query optimizations to enhance performance.
- Utilize UDFs for complex calculations and transformations: Leverage UDFs to simplify complex calculations, data transformations, or business logic within your SQL queries. Encapsulating these operations in functions can enhance code readability and maintainability.
- Test and validate UDFs: Thoroughly test and validate your UDFs to ensure they produce the expected results across different scenarios and input values. Consider edge cases and handle potential errors or exceptions gracefully within your functions.
- Document your UDFs: Provide clear and comprehensive documentation for your UDFs, including the purpose, input parameters, return types, and expected behavior. This documentation aids in understanding and maintaining the codebase.
JSON
In this section, we will explore the JSON support in Snowflake, which enables efficient handling and manipulation of JSON data within the database. We will provide an overview of JSON support in Snowflake, demonstrate Snowflake’s “SQL command” for working with JSON data, and offer valuable tips for effectively utilizing JSON capabilities in Snowflake.
Snowflake provides comprehensive support for JSON data, allowing you to store, query, and manipulate JSON documents seamlessly. JSON (JavaScript Object Notation) is a popular data format for representing structured and semi-structured data, making it flexible for various applications.
Advantages of JSON support in Snowflake
The advantages of JSON support in Snowflake include the following:
- Flexible data modeling: JSON support enables you to store and work with flexible schema structures, accommodating varying data shapes and evolving requirements.
- Efficient querying: Snowflake’s integrated JSON functions and operators allow for efficient querying of JSON data, making it easy to extract specific elements, filter data, and aggregate results.
- Seamless integration: JSON data can be seamlessly combined with structured data in Snowflake, enabling powerful analytics and insights across different data formats.
Example of Snowflake SQL code for Handling JSON Data
The following example is about parsing and extracting JSON elements.
— Extracting values from JSON data
SELECT json_extract_path_text(json_data, 'name') AS name, json_extract_path_text(json_data, 'age') AS age FROM json_table;

The following example is about modifying and transforming JSON data.
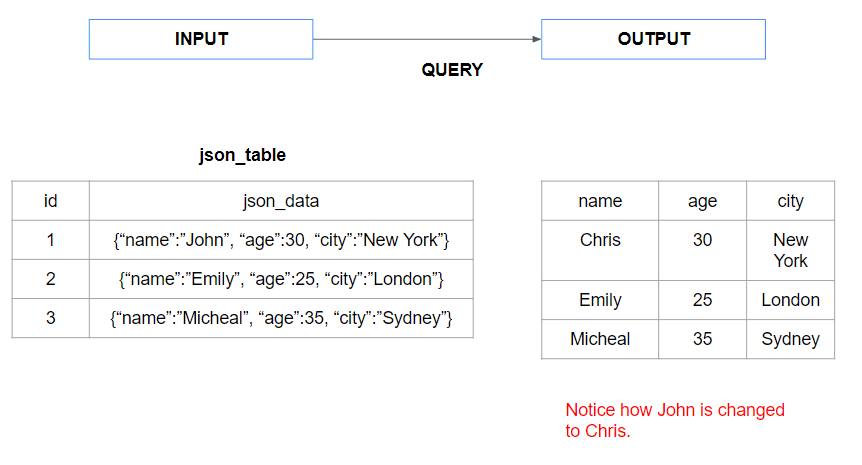
— Updating JSON values
UPDATE json_table
SET json_data = jsonb_set(json_data, '{name}', '"Chris"')
WHERE id = 1;
— Transforming JSON data to a table
SELECT t.key, t.value FROM json_table, lateral flatten(input => json_data) t;
Loading JSON data into Snowflake
Loading JSON data into Snowflake offers flexibility in handling semi-structured data and integrating it seamlessly with structured data within a data warehousing environment. Several methods and considerations for loading JSON data into Snowflake include bulk loading, real-time data ingestion using Snowpipe, and integrating JSON with structured data.
Bulk Loading of JSON Files:
Snowflake supports bulk data loading of JSON files, allowing you to load large volumes of JSON data into tables efficiently. Snowflake’s COPY command can load JSON files in a cloud storage service like Amazon S3 or Azure Blob Storage. The JSON data is automatically parsed and loaded into Snowflake tables.
Example:
COPY INTO my_table FROM @my_stage FILE_FORMAT = (TYPE = JSON);
Integrating JSON Data with Structured Data
Snowflake allows seamless integration of JSON data with structured data, enabling comprehensive analysis across different data formats. You can load JSON data into dedicated JSON columns within Snowflake tables or flatten the JSON data into structured tables using the FLATTEN function.
Example:
— Loading JSON into a dedicated JSON column
CREATE TABLE my_table ( id INTEGER, json_data VARIANT ); COPY INTO my_table (id, json_data) FROM @my_stage FILE_FORMAT = (TYPE = JSON);
— Flattening JSON into structured tables
SELECT id, t.key, t.value FROM my_table, LATERAL FLATTEN(input => json_data) t;
This allows you to query and analyze the JSON data alongside structured data using standard SQL queries.
Conclusion
In conclusion, this blog has covered various aspects of Snowflake SQL, ranging from useful SQL queries to dimensional modeling, stored procedures, functions, and working with JSON data. By leveraging these tips and examples, you can enhance your SQL skills and optimize your data manipulation and analysis tasks in Snowflake.
At Data Sleek, we understand the importance of efficient SQL techniques and best practices in maximizing the value of Snowflake for your organization. Our team of experts has extensive experience in Snowflake and can help you unlock the full potential of your data.
We are committed to empowering organizations like yours with our expertise in Snowflake SQL. Whether you need assistance with dimensional modeling, stored procedures, functions, JSON, or any other aspect of Snowflake, our team is here to support you and ensure you harness the full power of Snowflake for your data manipulation and analysis needs.
Contact Data–Sleek today to learn how we can help you optimize your Snowflake SQL implementations and elevate your data-driven capabilities.






