We’re often engaged in consulting projects where we are asked about a range of different database options for scalability, query performance and reliability. Which Database System is Right for Your Business?
SingleStore and ClickHouse are two popular database systems that are often considered for scalability, query performance, and reliability. When it comes to choosing the right database system for your business, it is essential to look at SingleStore vs ClickHouse in terms of their features, capabilities, and suitability for your specific needs.
If you’re also evaluating how SingleStore compares to other leading cloud databases, check out our in-depth guide on SingleStore vs Snowflake and SingleStore vs MySQL to understand differences in scalability, compute separation, and real-time analytics performance.
About ClickHouse and Singlestore
ClickHouse and Singlestore are both a column-oriented olap database management system (DBMS) with a query engine designed to handle large amounts of data and are used primarily for heavy analytical workloads (online analytical processing), which involve querying and analyzing data to gain insights and make decisions.
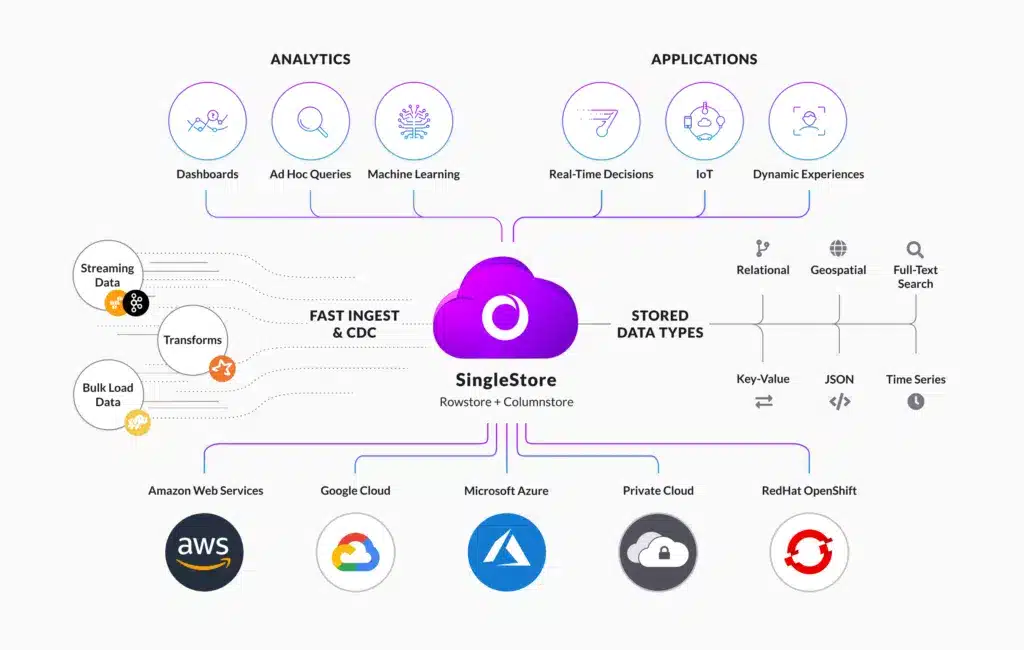
SingleStore is a distributed relational database known for speed, scale, loading large dataset at blazing speed, being able to handle large time series workloads, support for many different type of storage whether in memory, on disk, on using S3 and much more.
Some of the key features of ClickHouse and Singlestore includes:
- Fast query performance: ClickHouse and Singlestore are designed to deliver high query performance, even when working with massive amounts of dataset. They achieve this through a number of optimizations, including column -oriented storage, vectorized query execution, and the ability to process data in parallel across multiple nodes.
- Scalability: Both ClickHouse and Singlestore are highly scalable and can handle petabytes of data across large clusters of servers. It also supports sharding and replication, allowing you to distribute data across multiple nodes and ensure high availability.
- Support for complex queries: ClickHouse and Singlestore supports a wide range of SQL functions and syntax, as well as advanced features like window functions, subqueries, and joins.
- Real-time data processing: ClickHouse and Singlestore support real-time ingestion of data, making it well-suited for applications that require fast data processing and analysis, although Singlestore has pipeline features which makes it much easier to ingest data.
Some common use cases for this type of database engine include:
- Analytics and reporting: These DBMS are often used for business intelligence and analytics applications, where it can be used to analyze large volumes of data and generate reports and visualizations. Singlestore however supports transactions. Large amounts of data can be ingested, updated, on billions rows table, while still being able to perform aggregate queries.
- Ad tech: Singlestore is commonly used in the advertising industry to process large volumes of real-time data related to ad impressions, clicks, and conversions.
- IoT and time-series data: Singlestore is well-suited for processing and analyzing time-series data from sensors and IoT devices, as it can handle large volumes of data in real-time, and take advantage of the time_bucket feature.
- Log processing: Both databases can be used to store and analyze log data from servers and applications, allowing you to gain insights into system performance and identify issues.
Singlestore Innovates
In recent years, Singlestore has been pushing the envelope to become a database that can handle transactional (OLTP) and analytical queries simultaneously, also referred to as “translytical platform” which very few other databases support.
To see how organizations can fully harness this translytical power, explore our detailed guide on Maximizing the Power of SingleStore Database with Data Sleek, where we show real-world ways to optimize performance, scaling, and real-time analytics.
There are more new features like Code Engine – Powered by Warm, fast seeking into JSON column values, improved seek performance for string data types, recursive common table expressions, memory spill (never run out of memory for a query) etc…
Why we benchmark Singlestore against Clickhouse?
In our line of consulting, it’s not enough to offer anecdotes and opinions — the data is necessary to support our observations. Below you’ll find singlestore benchmark and clickhouse benchmark results using TPCH standard data.
Query Speed Is Not Just The Most Important Thing
We’re commonly asked about ClickHouse cloud as an option, likely because it’s free and queries are supposedly fast compare to other free analytical databases. Although both are true, it’s important to think about scalability, innovation, support, data ingestion, cloud storage, low latency, reliability, and architecture limitations, like needing to join several tables while ingesting large amount of data without unexpected behavior.
ClickHouse and SingleStore Details
The benchmarks for ClickHouse and SingleStore Cluster In a Box (CIAB) was performed on a 64GB, 8CPU, 200GB SSD Disk (similar to a r5.2xlarge EC2 instance). The dataset was stored on a 250 GB Digital Ocean Volume attached to the droplet. Data was ingested locally from the attached storage using the TPC-H benchmarks files — the largest file being 75GB (lineitem) for 600 MB rows.
SingleStore vs. ClickHouse Ingestion – 3 points
| Table Name | Total Rows | Total File Size | ClickHouse | SingleStore |
| customer | 15,000,000 | 2.3 GB | 11s | 22s |
| lineitem | 600,037,902 | 75 GB | 5m 4s | 11m 38s |
| nation | 25 | 2.2k | 0ms | 0ms |
| orders | 150,000,000 | 17GB | 1m 18s | 2m 49s |
| part | 20,000,000 | 2.3 GB | 13s | 24s |
| partsupp | 80,000,000 | 12 GB | 47s | 1m 34s |
| region | 5 | 1k | 0ms | 0ms |
| supplier | 1,000,000 | 137 MB | 2s | 3s |
Data Loading was done using 8 files (1 file per table for TPC-H), residing on the attached storage, using a bulk load method (see file at end of article). We did not test ingestion using Singlestore Pipelines which performed better in another test (in AWS). For the large tables, ClickHouse performed much better on the data load, twice as fast for largest tables.
Although data load time is important, it’s not the most critical point. Our main goal was to show case how fast queries are against large tables in ClickHouse Vs Singlestore when using joins.
Note: While ingesting using Load Data Infile in SingleStore, querying the table (select count(*)) does not return records until the load is completed. This result is different when using SingleStore’s Pipelines, which allows you to query the tables as data loaded. The record count will update each time the SingleStore Pipelines commit the batch of records (which can be specified).
Ingestion Conclusion
When it comes to ingestion, ClickHouse cloud was twice faster on average then SingleStore. Singlestore gets one point because it’s possible to run a query against a table where a large amount of data is being ingested into, no locking occurring using pipeline.
SingleStore pipeline ingestion is quite powerful. Not only can it connect to S3, Kafka, Azure Blog and HDFS, it can also support various formats including Parquet, CSV, TSV, JSON and more. SingleStore also offers transformational capabilities — Pipelines can be stopped and started again, without losing data. Lastly, because Pipelines are created with SQL, you can dynamically create and start them.
Points: SingleStore 1.5, ClickHouse 1.5
SingleStore vs. ClickHouse Queries – 3 points
Queries were performed on the same Digital Ocean instance. ClickHouse was installed to first perform the query test, then to perform the shutdown. Then, SingleStore was installed and set up as SingleStore-in-a-box (1 primary aggregator, and 1 leaf node).
| Query | Clickhouse | Singlestore | Speed Diff |
| 1 | 0s 0ms | 0s 20ms | 0 |
| 2 | 0s 322ms | 0s 40ms | 0 |
| 3 | 7s 727ms | 2s 960ms | 3 |
| 4 | 81s 626ms | 0s 440ms | 186 |
| 5 | 6s 470ms | 0s 170ms | 38 |
| 6 | 6s 359ms | 0s 710ms | 9 |
| 7 | 16s 397ms | 18s 110ms | 1 |
| 8 | 148s 0ms | 3s 610ms | 41 |
| 9 | 41s 135ms | 4s 300ms | 10 |
| 10 | 21s 876ms | 8s 370ms | 3 |
| 11 | 600s 0ms | 21s 630ms | 28 |
Although ClickHouse cloud ingests faster as seen in previous tests, results show that SingleStore clearly outperforms ClickHouse — especially when joining tables. Queries 1, 2 and 3 are simple queries against a single table: lineitem. As you can see, there are no major, notable differences between the two databases. These queries are handled within microsecond differences, which is not noticeable when manually running queries.
Performance starts to quickly degrade when ClickHouse cloud starts joining tables (query 4 to 11 in the graph). Query 4 (joining 2 tables and doing a limit) takes 440 milliseconds in SingleStore, and 81 seconds in ClickHouse. Queries 8-11 were actually failing in ClickHouse until we increased the amount of available memory. Additionally, ClickHouse was unable to complete query 11 — even after assigning 50GB of memory. SingleStore completed the query in 21 seconds.
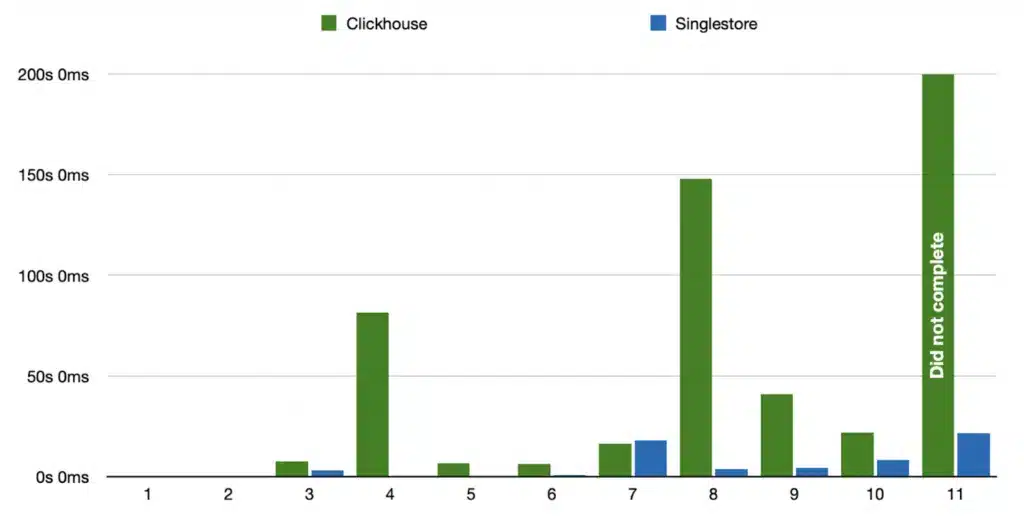
The shorter the bar, the better!
Queries Conclusion
When it comes to queries, ClickHouse can quickly query a single table, with SingleStore closely matching performance. When ClickHouse must join tables, performance degrades considerably. This is why the benchmarks listed on ClickHouse’s website are always against single (flattened) tables.
Points: SingleStore 2.5, ClickHouse 0.5
We would like to give ClickHouse one-half point because queries against single tables are very fast. But that is where ClickHouse performance stops. We have not even tested queries with Common Table Expressions (CTE), which ClickHouse seems to support.
Speed matters, but in retail analytics the real differentiator is how quickly you can turn raw sales data into decisions that shape customer experience.
Bala, Database Architect, Data-Sleek
GUI Administration & Monitoring – 3 points
Administering and monitoring your database is critical. Clickhouse has some open source GUI but they seem pretty limited, mostly running SQL select queries. Monitoring is possible via Grafana.
SingleStore comes with SingleStore Studio, which allows you to monitor and get a great overview of the cluster’s overall health:
- The dashboard shows Cluster Health, pipeline status, cluster usage and database usage.
- It looks at the difference in host CPU consumption, disk space used and how much memory is consumed.
- Database Metadata: Users can look at each database and dive in to see the stats about each table (total rows, compression, how much memory / disk space is consumed).
- Active Queries: Similar to “show process list” in MySQL, this allows users to see running queries.
- Workload Monitoring: You can start workload monitoring which profiles the activities running on a cluster, tracking all queries being executed — and quickly identify those that are most resource intensive.
- Visual Explain: A query profile can be saved, then loaded, into Visual Explain to see a detailed query plan
- SQL Editor: One of the most popular features, this allows users to run queries within the browser (just like Snowflake)
- Pipelines: Shows pipeline running
Points: SingleStore 2.5, ClickHouse 0.5
Advanced Features – 3 points
SingleStore provides full redundancy out of the box when using a cluster with at least 2 aggregators and 2 leaf nodes. Leaf nodes can use the High Availability feature, allowing data to be copied on each leaf to provide full redundancy. If a leaf goes down, the cluster can still be used. ClickHouse can be used also as a cluster but the implementation, configuration and administration is not as simple as SingleStore.
Stored Procedure
SingleStore supports stored procedures. Pipelines can ingest into stored procedures, allowing you to transform data or maintain aggregates (for example, a materialized view).
S3 Table
Both SingleStore and ClickHouse support S3 as a cloud storage engine, although SingleStore has implemented a more robust solution. In SingleStore, the S3 storage is created at the database level, meaning all tables created in that one database will use S3 storage. In ClickHouse, the storage is at the table level. SingleStore has also a memory / disk caching layer for hot data when using S3 storage, enabling great performance. When using S3 as a cloud storage layer for a database, data spills over to S3 if the disk gets full.
UDF, Time Series, Geospatial, etc.
SingleStore supports many advanced analytical functionalities including JSON extract, time series (time bucket), geospatial functions and more. The SingleStore database is really built for analytics.
PTR (Point-in-Time Recovery)
PTR enables system-of-record capabilities. Customers can now operate their SingleStore databases with the peace of mind that they can go back in time to any specific point, and restore any data lost from user error or failure.
Points: SingleStore 2.5, ClickHouse 0.5
Cost – 3 points
ClickHouse is free open source software, although there are now some paid options too. SingleStore provides a fully-featured free version for production that you can run up to 4 nodes in any environment you choose. For the cloud, SingleStore provides $500 in free credits if you prefer the managed service. ClickHouse does not provide redundancies — deploying a ClickHouse system in production is risky unless you have an in-house expert standing by. SingleStore’s support is excellent, and they’ll answer questions in their forum (even if you’re not a customer). [1] [LF2]
Points: SingleStore 1, ClickHouse 2
Final Conclusion
As DBAs with some Data Engineering experience, we can conclude that SingleStore offers a much stronger solution than ClickHouse. The performance of the queries when joining tables is obvious — queries were 3-186x faster. Our SingleStore consulting team can help you implement and optimize SingleStore for your specific workloads.
In many cases, memory had to be increased using SET max_memory_usage = 40000000000 before running the query or it would fail. ClickHouse is another memory database that seems to heavily rely on scanning rows quickly in memory to generate results. Performance takes a big hit when tables need to be joined, which SingleStore handles without issue.
Furthermore, SingleStore consistently adds new features, improves its admin and monitoring tools and now supports S3 storage. The number of features available in SingleStore for analytics surpasses those of ClickHouse. SingleStore also supports modern data engineering ingestion, allowing ingestion from Kafka, S3 and more by just using a few lines of SQL code.
Total Points
| SingleStore | ClickHouse |
| 10 | 5 |


