MySQL is a robust, open-source relational database that has existed for decades. It’s a simple and effective database server for DMBS ( Database Management Systems).
Some of the biggest websites have used it, and it has become one of the most popular databases today. Unfortunately, as much as data professionals love it, MySQL isn’t perfect. In fact, scaling MySQL innodb engine can be challenging at times because it was designed for a different purpose than those today in analytics—namely, big data queries against enormous datasets.
There are ways to address these limitations, though! In this post, we’ll go over some methods for scaling MySQL for data analytics so you can keep your database performant.

What is MySQL, and how is it used in database management?
MySQL is an open-source relational database management system that facilitates storing, organizing, and managing data. It’s widely used for web applications to manage large databases. MySQL supports SQL (simple query language), making it easy to interact with databases to process data (update and modify data) and perform select queries.
Known for its reliability and ACID compliance, InnoDB is well-suited for applications requiring transactions and data integrity. However, when it comes to data analytics workloads, some may question if InnoDB is the right choice due to its row-level locking mechanism, which can lead to performance issues and table locks. To learn how to resolve table locks, check out our dedicated guide on troubleshooting Mariadb table locks on AWS RDS.
The Importance of Data Analytics in Decision-Making
Data analytics plays a vital role in guiding strategic decision-making for modern businesses. By harnessing data insights, organizations can gain a competitive advantage, improve operational efficiency and actionable insights, and enhance customer experiences.
In the MySQL context, selecting the appropriate database engine, such as InnoDB, is crucial for effective data processing and analysis, which in turn enhances business decisions.
Introduction to Data Analytics in MySQL
There are many types of data analytics, from predictive data analytics to business analytics, prescriptive data analytics, and descriptive data analytics.
Analyzing historical data is crucial for predictive analytics. Businesses can make informed decisions about future strategies and outcomes by studying past data trends and patterns. This data analysis allows companies to forecast future trends, identify potential risks, and optimize performance. Utilizing historical data in MySQL empowers businesses to make data-driven decisions that can lead to improved efficiency and profitability.
MySQL opens up a world of possibilities for organizations looking to derive valuable insights from their data at a lower cost. This DMSB is now offered as a managed database solution by major cloud providers such as AWS, Google Cloud, Azure, and Digital Ocean, and it provides secure and reliable data storage.
This is crucial for data analysts looking for a DBMS to query using power bi or other specific tools for analytics.
Types and Techniques of Data Analytics for MySQL
Regarding data analytics in MySQL, various types and techniques can be employed to extract valuable insights from your database.
The possibilities are vast, from simple aggregations and joins to more advanced predictive modeling and machine learning algorithms.
You can efficiently perform complex data analysis tasks within your MySQL environment by utilizing tools like SQL queries, stored procedures, and user-defined functions.
In the following sections, we will explore these different data analytics techniques for MySQL, including data mining, to help you optimize your analytical processes and drive informed decision-making.
Why MySQL InnoDB Engine May Struggle with Aggregated Queries?
Aggregated queries, such as SUM, COUNT, and GROUP BY, are fundamental in data analytics because they allow for the summarization and extracting of meaningful insights from large datasets. However, these queries can be performance-intensive, particularly in traditional row-based storage engines like MySQL’s InnoDB.
1. Row-Based Storage: InnoDB, like most traditional relational database engines, uses a row-based storage format. This means that data is stored and indexed by rows, which is efficient for transactional operations (e.g., INSERT, UPDATE, DELETE) but less so for analytical queries that often require scanning large portions of the table(s) in the database to compute aggregates.
2. I/O and CPU Overhead: Aggregated queries often require scanning large volumes of data, leading to significant I/O operations and CPU processing. InnoDB’s row-based storage format is not optimized for these operations, resulting in slower performance compared to engines specifically designed for analytics.
3. Lack of Columnar Compression: InnoDB doesn’t utilize columnar compression, which can significantly reduce the amount of data that needs to be read from disk during analytical queries. This lack of optimization means that more data must be processed, leading to higher latency in query responses.
Enhancing Performance with Summary Tables
One effective technique to speed up analytical queries in MySQL, mainly when using tools like Tableau or PowerBI, is to precompute results and store them in summary tables.
Summary Tables: These are tables where aggregated data is precomputed and stored, especially for unstructured data, reducing the need for the database engine to perform expensive aggregation calculations on the fly. For example, if your analysis frequently involves summing sales data by month and region, you could create a summary table that already contains these sums. Queries against this summary table will be much faster because the complex aggregations have already been performed.
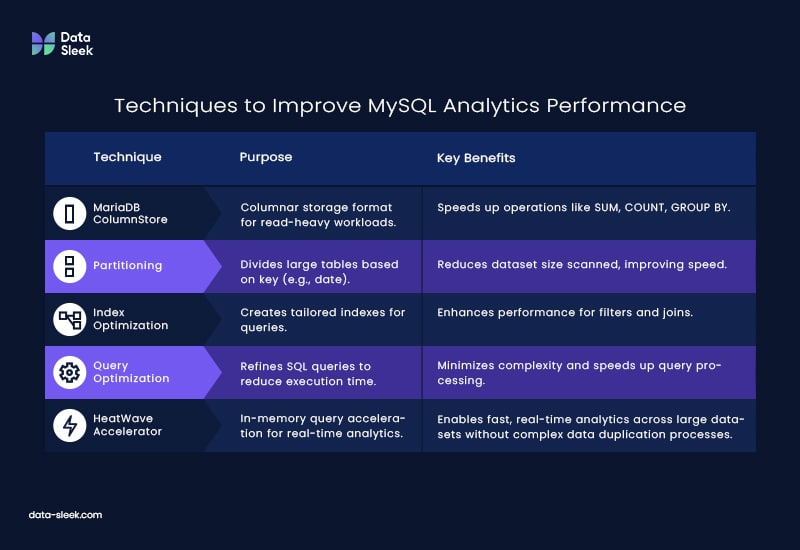
Additional Techniques to Improve MySQL Analytics Performance
Beyond summary tables, there are other strategies to optimize MySQL for analytics and data visualization, especially when using it in conjunction with BI tools like Tableau or PowerBI.
1.MariaDB ColumnStore: MariaDB’s ColumnStore engine is an excellent alternative for users seeking better performance in analytical queries. ColumnStore uses a columnar storage format that is better suited for read-heavy, analytical workloads. Storing data in columns rather than rows reduces the amount of data that needs to be read and processed during queries, significantly speeding up operations like SUM, COUNT, and GROUP BY.
2.Partitioning: Partitioning large tables based on a specific key (e.g., date ranges) can help reduce the dataset size that needs to be scanned for a query. This can lead to faster query performance, especially when working with large datasets.
3.Index Optimization: Carefully designed indexes can significantly improve query performance, especially for frequent filter conditions and join operations. However, indexes must be carefully chosen for aggregated queries to ensure they improve rather than hinder performance.
4.Query Optimization: Often overlooked, optimizing the SQL queries themselves can have a significant impact. Avoiding unnecessary joins, using indexed columns in WHERE clauses, and minimizing the complexity of subqueries can help reduce query execution time.
The techniques mentioned are effective for small datasets and low concurrent user activity. However, MySQL may encounter performance issues for large datasets (100 million rows) and more than ten simultaneous users, whether using partitioning, index optimization, or a MariaDB column store. The primary reason is that this database server was not designed to handle queries in large data stores.
MySQL databases can be integrated with data warehouses to manage large volumes of data efficiently. This integration allows businesses to gain insights through data analysis and reporting tools. The HeatWave in-memory query accelerator is a valuable feature that enables real-time analytics across data warehouses and lakes without complex data duplication processes. Thus, MySQL offers a comprehensive solution for businesses looking to streamline their data management and analytics capabilities.

Scale Read Capacity With Primary-Replica Configuration
MySQL can handle big data analytics to a certain point. Using Primary-REplica is usually the first approach data engineers will take, but as tables and datasets increase in size, it becomes costly. Besides reporting, analytics uses different types of queries that are not efficient with the InnoDB engine.
To scale read capacity, you can use replication. In a Primary-Replica configuration, there is one primary database server and multiple replicas replicating from the central database. This means that if your data set is large enough to warrant adding more read capacity, you can add new replicas without any additional maintenance overhead on the database side of things. AWS RDS is one of the most popular managed database services in the cloud.
Primary replica replication also has some drawbacks. The most significant risk with this type of configuration is replication lag; if something happens on your primary database or even during a planned maintenance event (such as upgrading MySQL), it could take some time for your replica(s) to catch up with their transactions. This time lag depends on how much data has been inserted into or updated in those transactions since they were committed by the original transaction creator (in this case, being committed by your application). Another solution to guarantee limited lag is to use AWS Aurora MySQL solution.
Another drawback of primary-replica replication is performance: because all reads must go through a single point, they will be slower than if they were coming directly from a sharded cluster where multiple nodes could serve them simultaneously (like what we will do below). However, this drawback may not matter depending on how often your queries may run and how long they take; if most queries are less than 1ms and only need one row at most times then it shouldn’t affect them too much!

Is MySQL InnoDB A Good Solution for Data Analytics?
InnoDB is now the default storage engine for MySQL. InnoDB is a transactional engine, meaning all transactions are isolated from other transactions on your database server. Additionally, InnoDB supports foreign keys and locking — handy features for ensuring consistency across tables — and clustering and replication. MySQL has also improved InnoDB engine partitioning, allowing it to detach partitions and move them to other tables efficiently.
However, this is insufficient to optimize for the demands of analytical queries. When a database needs to ingest large amounts of data by batches on micro-batches, there is a good chance your table will lock, and you won’t be able to perform analytical types of queries. Large data batches will take time to replicate to your replica(s), so data latency will occur, and queries won’t be able to take advantage of them.
The InnoDB engine is not meant for analytical queries, especially complex ones. This is why the columnar DBMS was introduced long ago (1969) for OLAP-type queries.
Faster Queries with SSD Disk and High RPM
If you have a sufficient budget, you can use a Solid-State Drive (SSD) instead of traditional hard drives. You’d want this because SSDs are faster than hard drives and can save you time when loading your data into MySQL. SSD disks also require less power than mechanical disks, making them more energy efficient. They are also more reliable and durable because the disk has no moving parts to break down over time. Finally, they have higher capacities than their mechanical counterparts, so they can simultaneously store more data on each drive unit.
Evaluate the Indexes
Let’s talk about how best to use indexes. In some cases, indexes can be a major bottleneck for queries. If your database is over-indexed, you may be able to get it to perform faster by removing some of the redundant indexes or adding more RAM to your server so that MySQL can store more table data in memory and avoid searching through disk-based indexes.
To see what indexes are being used by MySQL during query execution (this is advanced stuff), use the EXPLAIN command:
Efficiently Scaling MySQL Queries
Consider using a primary replica, as mentioned above.
If your indexes are not well-designed, they can slow down queries or even cause them to fail. You should evaluate the indexes for any poorly performing tables and tune them accordingly.
Additionally, sharding is another way of scaling your database by distributing it across multiple nodes in your cluster so that each node has its own instance of MySQL installed. This allows each node to handle the full load independently while sharing data between nodes as necessary (i.e., when replicating).
Sharding, sometimes called Horizontal Scaling, is a partitioning technique that splits data across multiple servers. It distributes the data in a way that allows for parallel processing and scales out read and write capacity.
For example, if you have 10 million users on your site and receive 100 new user requests per second, sharding will help you distribute these requests among multiple shards so they can be processed more efficiently than if they had to go through one server. Sharding also allows you to scale out read capacity by allowing each shard to handle its own reads while maintaining a central database server that handles all write operations.
Although some services provide a MySQL sharding solution, the best alternative is to use Singlestore. Singlestore supports the MySQL protocol and can scale or replace your MySQL, especially for real-time analytics.
Data-Sleek is a Singlestore partner and we have migrated several MySQL infrastructures to Singlestore to speed up MySQL queries running against tables with billions of rows.

Conclusion: Is MySQL InnoDB suitable for Data Analytics?
MySQL is a powerful and reliable database management system, particularly for transactional workloads. However, when it comes to data analytics, particularly with large datasets and complex queries, the limitations of MySQL’s InnoDB engine become apparent. Aggregated queries like SUM, COUNT, and GROUP BY can lead to significant performance bottlenecks due to InnoDB’s row-based storage format, lack of columnar compression, and the resulting I/O and CPU overhead.
While techniques like summary tables, index optimization, and partitioning can improve performance, they may not be sufficient for all scenarios, especially as data volumes and concurrent user activity increase, for those looking to push the boundaries of MySQL’s analytical capabilities, alternatives like MariaDB ColumnStore or migrating to a more suitable platform like Singlestore or Snowflake offer compelling options.
At Data-Sleek, we specialize in helping businesses optimize their database infrastructures for better performance and scalability. Whether you’re looking to enhance your MySQL environment or explore alternatives, our expertise can guide you to the best solution for your data analytics needs.
Frequently Asked Questions (FAQ)
1. Why does MySQL struggle with large-scale analytical queries?
MySQL’s default storage engine, InnoDB, uses a row-based storage format that is optimized for transactional operations but not for analytical queries. Aggregated queries like SUM, COUNT, and GROUP BY require large data scanning, leading to significant I/O and CPU overhead.
2. What are some techniques to improve MySQL’s performance for data analytics?
Some techniques include using summary tables, optimizing indexes, partitioning large tables, and query optimization. Additionally, considering alternative storage engines like MariaDB ColumnStore or migrating to a more analytical-friendly platform like Singlestore can further enhance performance.
3. What is the role of summary tables in improving query performance?
Summary tables store pre-computed aggregated data, reducing the need for MySQL to perform expensive calculations on the fly. This can significantly speed up analytical queries, especially using BI tools like Tableau or PowerBI.


